چرا ارزش گذاری املاک به چشم انداز رایانه ای نیاز دارد

چرا ارزش گذاری املاک به چشم انداز رایانه ای نیاز دارد
در مقاله اخیر من یک ابزار تجزیه و تحلیل برنامه وام مسکن ارائه کردم که از AI برای اعتبارسنجی برنامه ها استفاده می کند. پس از خواندن آن مقاله ، مشتری که سال گذشته با او کار کردیم (Vin Vomero ، بنیانگذار Foxy AI) تماس گرفت تا ببیند آیا می توانم مقاله ای مشابه در مورد کارهایی که برای ارزیابی املاک و مستغلات برای آنها انجام دادیم ، بنویسم.
< p> مشکلی که ما سال گذشته روی آن کار کردیم یک مشکل شگفت انگیز بود: برآورد قیمت خانه بد است. لیست ها دائماً بیش از حد یا کم ارزش می شوند و ارزش گذاری یک خانه یک عامل کلیدی نه تنها برای خریدار و فروشنده بلکه برای ضامن وام مسکن است که خانه برای آن وثیقه است. مدلهای ارزیابی خودکار (AVM) اغلب توسط م institutionsسسات مالی برای تصمیم گیری در مورد همه چیز ، از وامهای صاحب منزل تا محدودیت کارت اعتباری استفاده می شود. این فقط مربوط به فروش خانه نیست. درک ارزش خانه برای کاهش ضرر و مدیریت ریسک اعتباری بسیار مهم است. بهترین راه برای ارزیابی ارزش خانه چیست؟ بلکه یک ضرورت رقابتی است. به زودی ، مدلهای ارزشیابی بدون سطح هوش مصنوعی منسوخ می شوند.
بهترین راه برای ارزیابی ارزش خانه چیست؟ بلکه یک ضرورت رقابتی است. به زودی ، مدلهای ارزشیابی بدون سطح هوش مصنوعی منسوخ می شوند. به نقل از راب می ، مدیرعامل و بنیانگذار Talla ، "من را شگفت زده می کند که برخی از شرکتها به دلیل نداشتن هوش مصنوعی دیر به کار می گیرند. مطمئن باشید کجا باید آن را اعمال کنید یا چقدر خوب کار می کند. من فکر می کنم آنها نمی فهمند که تا زمانی که این چیزها مشخص شود ، بسیار عقب خواهند ماند. AVM هایی که در سراسر جهان استفاده می شوند باید بسیار بهتر باشند ، زیرا تا کنون به طور عینی وحشتناک بوده اند. این واقعیت که هوش مصنوعی می تواند 15 درصد در پیش بینی قیمت بهبود یابد ، نشان می دهد که مدل های سنتی تا به حال چقدر ضعیف عمل می کردند.


 وضعیت خانه فراتر از تعداد اتاق خواب و حمام و مربع است فیلم یک مدل ارزش گذاری باید فهرست را مشاهده کند.
وضعیت خانه فراتر از تعداد اتاق خواب و حمام و مربع است فیلم یک مدل ارزش گذاری باید فهرست را مشاهده کند. چرا ارزش گذاری خانه بد است؟ آنها بر داده های قدیمی ، داده های عددی ، داده های سرشماری ، داده های IRS و داده های فروش ایالتی/منطقه ای تکیه می کنند که ممکن است منعکس کننده سرمایه گذاری انجام شده در خانه نباشد. حتی گره زدن همه این منابع داده با هم گاهی تصویری ناقص به شما می دهد. اگرچه مدلهای سنتی AVM سریع و ارزان هستند ، اما نمی توانند کیفیت و وضعیت یک ملک را بدون در نظر گرفتن واقعی آن در نظر بگیرند و در نتیجه دقت یک ابزار کلیدی در صنعت خدمات مالی را محدود کنند.
< p> چرا این مشکل سختی است؟ خوب ، الگوریتم های رایانه ای سنتی دوست دارند اعداد را با استفاده از فرمول ها پردازش کنند ، نه تصاویر خانه ها. هیچ فیلدی در فهرست "یک زنگ در پشت بام گم شده است" وجود ندارد. برای درک درست ، مدل هوش مصنوعی باید به تصاویر نگاه کند و بفهمد که تصاویر چگونه بر قیمت تأثیر می گذارند. به طور خاص ، مدل باید در مورد اتاق مورد نظر خود بیاموزد ، بافتها ، رنگها را درک کند ،و اشیاء داخلی/خارجی این راه حل را مانند یک نوآوری در وب سایت دوستیابی در نظر بگیرید که در آن تا به حال ، هیچکس نمی توانست تصاویر پروفایل افراد را مشاهده کند ، و در عوض آنها فقط قد ، وزن و سایر داده های زیست پزشکی را مشاهده می کردند. واضح است که یک تصویر به هزار کلمه می ارزد. حتی وقتی به عنوان یک راه حل هوش مصنوعی پیاده سازی می شود ، بدست آوردن یک مدل رگرسیونی برای درک این همه اطلاعات در مورد یک لیست و درک آن در مورد همه موارد و استثنائات خاص ، کمی کابوس است. من از جزئیات راه حل فنی درباره ساختن AVM سخت می گذرم و در عوض روی موارد استفاده جدیدی که Foxy AI به میز می آورد تمرکز می کنم.
تصاویر موجود در یک لیست می تواند داستانی در مورد ارزش گذاری املاک به ما بگوید که می تواند توسط روش سنتی افزایش یابد داده های عددی ، طبقه ای و متنی مرتبط با فهرست املاک. به عنوان مثال ، روکش گرانیت نشان می دهد که پول در خانه گذاشته شده است. عوامل ظریف مانند وضعیت رنگ روی دیوارها ، در مورد قیمت فروش مورد انتظار برای یک لیست به ما چیزهای زیادی می گوید. مجموعه داده مورد استفاده برای آموزش AVM اساساً نوع داده معمولی است که AVM های سنتی بر اساس آن ساخته شده اند ، اما با داده های اضافی زیادی از تصاویر و منابع دیگر تقویت شده است.
ما نمونه اولیه اولیه را سال گذشته تحویل دادیم. نمونه اولیه ای که برای Foxy AI توسعه دادیم اکنون بسیار بالغ شده است و بر روی یک مجموعه داده واقعاً نفس گیر آموزش دیده است. در حال حاضر ، به لطف پیشرفت در الگوریتم ها و قدرت محاسباتی ، می توانیم از ابزارها به نحوی استفاده کنیم که قبلاً امکان پذیر نبود. درک گرادیان در کیفیت در میلیون ها ویژگی در حال حاضر یک واقعیت است.

تحقیقات Foxy AI این رویکرد AVM جدید را با ترکیب بینایی رایانه و یادگیری عمیق به بازار عرضه کرده است تا کیفیت و وضعیت املاک مسکونی را ارزیابی کند. کل سیستم از طریق API ها در معرض دید قرار می گیرد تا بتوانید آن را بر روی سایر مواردی که استفاده می کنید بچسبانید. این محصول از تکنیک های آموزشی پیشرفته و مجموعه ای از مدلهای پیش بینی داخلی برای طبقه بندی نوع اتاقهایی که مجموعه تصویر ارائه شده را تشکیل می دهند و کیفیت و وضعیت ویژگی موضوع را تعیین می کند ، برای افزایش دقت ارزیابی استفاده می کند.
واقعاً رویکردهای جالبی وجود دارد که توسط API نشان داده می شود ، مانند نقطه پایانی برای تبدیل تصاویر به بردار ، راهی برای یافتن خواص قابل مقایسه (عوامل آن چیزها را دوست دارند) و سیستمی برای تشخیص اشیا ، تکمیل ها ، صحنه ها و موارد دیگر. و بنابراین می توانید تصمیم بگیرید که از API برای استخراج ویژگی ها از یک لیست موجود استفاده کنید یا فقط از API برای بدست آوردن داده های ارزشیابی بهتر استفاده کنید.
اگر به AVM های سنتی اعتماد دارید و در حال دریافت هستید پایان ارزیابی های نادرست ، ارزیابی این راه حل برای شما واقعاً جالب خواهد بود. میلیاردها دلار به معنای واقعی کلمه در خطر است ، بنابراین حتی افزایش ناچیز دقت نیز واقعاً بر شاخص های کلیدی عملکرد (KPI) برایکاهش ریسک وام دهی ، افزایش قدرت وام دهی و غیره. اگر می خواهید خودتان این جادو را تجربه کنید ، در بتا خصوصی ثبت نام کنید.
در اینجا پیوندی به Foxy در رسانه متوسط وجود دارد و امیدوارم درک کنید که چرا اینقدر جالب است. این فناوری امکانات جدیدی را باز می کند مانند شبیه سازی آنچه که یک خانه خیالی برای آن می فروشد و استفاده از آن برای انجام کار ناک دان و ایجاد برآورد به عنوان پیمانکار. قابلیت های بسیار جذاب ماشین حساب وجود دارد که به سادگی تا به حال وجود نداشت. راه حل همه در یک API ساده پیچیده شده است: https://www.foxyai.com/doc-api/#api-endpoints
و بنابراین ، در نتیجه ، AVM ها مختل می شوند و موسسات مالی باید توجه داشته باشید.
اگر از این مقاله در مورد AI برای ارزیابی املاک و مستغلات خوشتان آمد ، دکمه دنبال کردن را فشار دهید ، دست بزنید و به برخی از خواندنی ترین مقاله های گذشته من نگاه کنید ، مانند "چگونه قیمت پروژه AI »و« نحوه استخدام مشاور هوش مصنوعی ». همچنین ، Foxy AI را بررسی کنید. علاوه بر مقالات مرتبط با کسب و کار ، مقالاتی نیز تهیه کرده ام که درمورد مسائل دیگری که شرکت هایی که به دنبال یادگیری عمیق ماشین هستند ، مانند "یادگیری ماشین بدون ابر یا API" با آنها روبرو شده است.
در مقاله ای آینده ، چیزی را که مدتی است روی آن کار می کنیم ، ارائه می دهد که به شرکت ها کمک می کند تجزیه و تحلیل گزارش های بدون ساختار خود را در طول ممیزی داخلی خودکار کنند.
تا دفعه بعد!
-دانیل
daniel@lemay.ai ← سلام کنید. Lemay.ai 1 (855) LEMAY-AI
سایر مقالاتی که ممکن است از آنها لذت ببرید:
نشان Lisp یک رایانه مستقل و متناسب با برنامه نویسی Lisp است
نشان Lisp یک رایانه مستقل و متناسب با برنامه نویسی Lisp است
Lisp یک زبان برنامه نویسی سطح بالا است ، مانند پایتون ، ویژوال بیسیک و PHP. این دومین زبان قدیمی سطح بالا-با استانداردهای مدرن ما-درست بعد از Fortran است. اما ، هنوز هم بسیار محبوب است و دارای چندین گویش پر رونق است. دیوید جانسون دیویس راهی برای برنامه ریزی در لیسپ در حال حرکت می خواست ، و چه راهی بهتر از این با نشان وجود دارد؟

همانطور که احتمال می دهید این نشان لیسپ به شدت از نشان بلگراد ووجا آنتونیک الهام گرفته شده است. این نشان ، که به شرکت کنندگان در Hackaday Supercon 2018 نیز اهدا شد ، یک رایانه دستی است که می تواند برای اجرای و برنامه نویسی کد BASIC استفاده شود. جانسون دیویس قبلاً رایانه کوچک کوچک Tisp Lisp 2 را طراحی کرده بود ، اما برای این کار به یک صفحه کلید خارجی نیاز داشت. برای نشان Lisp ، او یک صفحه کلید روی صفحه اضافه کرده است تا بتوانید Lisp را در هر کجا که هستید برنامه ریزی کنید-مخصوصاً کنفرانس بعدی شما!

این نشان Lisp در کف دست شما قرار می گیرد ، اما دارای قابلیت های زیادی است. مجهز به ATmega1284 است و دارای صفحه نمایش OLED مقیاس خاکستری 42x8 ، پین های ورودی و خروجی است و می تواند دستگاه های خارجی را از طریق I2C یا SPI کنترل کند. مهمتر از همه ، صفحه کلید دکمه ای لمسی به طور خاص با در نظر گرفتن برنامه نویسی Lisp طراحی شده است. اگر می خواهید نشان Lisp خود را داشته باشید ، جانسون دیویس همه فایل ها را در GitHub ارائه کرده است. همچنین می توانید PCB ها را مستقیماً از OSH Park با قیمتی حدود 50 دلار سفارش دهید. 
احتمالات و آمار برای چشم انداز رایانه 101 - قسمت 1
احتمالات و آمار برای چشم انداز رایانه 101 - قسمت 1
من معتقدم درک مفاهیم اساسی در مورد یادگیری چیزی پیشرفته بسیار مهم است. چرا؟ زیرا اصول اساسی مبنایی است که شما می توانید دانش پیشرفته خود را بر اساس آن ایجاد کنید. اگر چیزهای بیشتری را بر اساس ضعف قرار دهید ، در نهایت می تواند از هم جدا شود ، به این معنی که هیچ یک از مطالبی را که آموخته اید به طور کامل درک نمی کنید. بنابراین ، بیایید سعی کنیم اصول اولیه را عمیقا درک کنیم.
در این مجموعه ، من در مورد احتمال و آمار بینایی رایانه توضیح خواهم داد. به طور عمده از کتاب درسی: "بینایی رایانه ای: مدل ها ، یادگیری و استنباط" نوشته دکتر سیمون جی. کتاب درسی عالی و دقیق است وب سایت زیر دارای انواع مواد از اسلایدهای PPT برای هر فصل ، PDF ، و غیره است. من اکیداً توصیه می کنم که برای درک مطالب از کتاب درسی استفاده کنید. در این سری از مقالات من ، من قصد دارم خلاصه و چند ایده اضافی را برای شما بیان کنم تا بتوانید مفاهیم را به راحتی درک کنید.
مطالبی که در این مقاله آورده شده است:
در کتاب درسی ، عمدتا از فصل 2 است. /uli>
مقدمه ای بر احتمالات و متغیرهای تصادفی
مطمئن هستم شما در مورد نقطه احتمال یاد گرفته اید ما همچنین هنگام تصمیم گیری ناخودآگاه در زندگی واقعی از آن استفاده می کنیم. اگر فکر می کردید به احتمال زیاد در تصمیمی که می خواهید بگیرید موفق خواهید شد ، به دنبال آن خواهید بود. در غیر این صورت ، شما نمی خواهید. این یک زمینه جالب برای مطالعه است ، اما گاهی اوقات ممکن است مشکل باشد. بنابراین در این بخش از مقاله ، بیایید به بررسی احتمال احتمالی بپردازیم و شما را با مفهومی به نام "متغیر تصادفی" آشنا کنیم.
فرض کنید یک کارت در دست دارید. و شما در حال ترک کارت هستید. احتمال اینکه کارت در هنگام دروغ گفتن روی زمین قرار بگیرد چقدر است؟

احتمالا در زندگی واقعی٪ (مانند 80٪ احتمال بارندگی) نشان داده می شود ، اما وقتی در ریاضی با احتمال برخورد می کنیم ، اغلب آنها را با استفاده از اعشاری (به عنوان مثال 0.5 برای 50 درصد). احتمال اندازه گیری احتمال وقوع یک رویداد ، نشان دهنده اعداد بین 0 تا 1 است.
متغیر تصادفی (RV) متغیری است که نتیجه علاقه ما را نشان می دهد. وقتی در مورد رها کردن کارت صحبت کردیم ، مثال بالا را ببینید. RV x برای نشان دادن وضعیت کارت استفاده می شود. این فقط 2 حالت دارد ، یا رو به بالا (x = 1) یا رو به پایین (x = 0). اگر با برنامه نویسی آشنا هستید ، مانند سایر متغیرهایی که می خواهید استفاده کنید. RV می تواند هر زمان که رویداد رخ می دهد حالت خود را تغییر دهد. بنابراین اگر یک کارت را 5 بار بریزید ، x می تواند [0 ، 0 ، 1 ، 0 ، 1] باشد. این به ما احتمال موقت سیستم را می دهد. از آنجا که ما 3 رو به پایین (x = 0) از خارج داریم5 آزمایش ، احتمال رو به پایین کارت Pr (x = 0) = 3/5 = 0.6 است. از سوی دیگر ، احتمال رو به روی کارت (x = 1) 2 از 5 است بنابراین Pr (x = 1) = 2/5 = 0.4 خواهد بود. توجه داشته باشید که مجموع همه حالتها (x = 0 و x = 1) 1 است و اگر همه حالتهای ممکن را جمع کنید همیشه اینطور است.
مقدمه ای بر تابع چگالی احتمال (PDF)
اکنون می دانید که احتمال و متغیر تصادفی چیست. بیایید در مورد تابع چگالی احتمال صحبت کنیم (اغلب مخفف PDF است ، نه نوع فایلی که اغلب استفاده می کنید!). این نکته بسیار مهمی است که باید به احتمال زیاد به خاطر بسپارید زیرا می توان روی آن تکیه کرد. p> 
این یک نسخه مجزا از تابع چگالی احتمال فرض کنید عرض هر میله همیشه 1 است. سپس مساحت Pr (x = 0) 0.4 * 1 = 0.4 است. همین امر در مورد Pr (x = 1) صادق است. توجه داشته باشید که مجموع تمام ناحیه ها همیشه 1 هستند. این امر در صورت حرکت به حالت مداوم تغییر نمی کند.
هر دو طرح توزیع یکسانی را نشان می دهند. تنها تفاوت در پیوسته یا گسسته بودن آن است. در علم داده ها ، به ویژه هنگامی که ما داده ها را با برنامه نویسی ارائه می دهیم ، به احتمال زیاد با داده های گسسته سروکار دارید که در آن چندین سطر و ستون دارید ، هر سلول حاوی یک نقطه داده واحد است.
بیایید به یک مثال ساده در زیر نگاهی بیندازیم. فرض کنید 2 متغیر تصادفی x و y دارید ، x نشان دهنده باران یا نه باران است ، y نشان می دهد که چتر دارید یا نه. فرض کنید که احتمال هر کدام را می دانید و چیزی شبیه به موارد زیر دارید:

در حال حاضر ، هر یک از آن دو شرط از یکدیگر جدا شده اند. اما ما می خواهیم احتمال ترکیب آنها را بدانیم. اینجاست که "احتمال مشترک" مطرح می شود.
بیایید یک مثال بزنیم. احتمال اینکه باران ببارد و چتر داشته باشید چقدر است؟ (خدا را شکر شما یکی دارید!) این مورد ما 1 است. ما احتمال Pr Pr (x = 1 ، y = 1) ، x = 1 به معنی احتمال بارندگی ، y = 1 به معنی چتر دارید. مورد 2 بدترین سناریو است. باران می بارد و شما چتر ندارید. مفصلاحتمال Pr (x = 1 ، y = 0) است.
 < /img>
< /img> بنابراین با مرور مثال های بالا ، امیدوارم که اندکی از احتمال مشترک استفاده کرده باشید. به عبارت کلی ، احتمال مشترک احتمالی است که احتمال وقوع دو (یا بیشتر!) رویداد را با هم و در یک نقطه در زمان محاسبه می کند.
فقط برای ارائه دیدگاه دیگری ، بیایید سعی کنیم برای تجسم آنچه احتمال مشترک است. فرض کنید 2 متغیر تصادفی (x و y) دارید و می خواهید از لحاظ بصری احتمال مشترک بودن آن را بدانید. به عنوان مثال به نظر می رسد که در زیر آمده است.
 < p> به این موضوع مانند یک نقشه کانتور فکر کنید. منطقه تیره (به سمت سیاه) در پایین است و با روشن شدن رنگ (به سمت زرد) ، ارتفاع نیز بالاتر می رود. در اصل ، شما سعی می کنید با نگاه کردن به یک نقشه دو بعدی ، منظره (که سه بعدی است) را درک کنید.
< p> به این موضوع مانند یک نقشه کانتور فکر کنید. منطقه تیره (به سمت سیاه) در پایین است و با روشن شدن رنگ (به سمت زرد) ، ارتفاع نیز بالاتر می رود. در اصل ، شما سعی می کنید با نگاه کردن به یک نقشه دو بعدی ، منظره (که سه بعدی است) را درک کنید. بنابراین در مورد احتمال مشترک ، این به ما چه می گوید؟ یک نکته مهم این است که کل ناحیه احاطه شده توسط جعبه مربع سیاه همیشه برابر 1 است. زمانی را که در مورد تابع چگالی احتمال (PDF) صحبت کردیم به خاطر دارید؟ جایی که مساحت باید همیشه 1 باشد؟ اینجا هم همینطور است از آنجا که ما در مورد احتمال صحبت می کنیم ، مجموع تمام احتمالات مشترک احتمالی در اینجا باید 1 باشد. جنبه دیگر این است که ارتفاع است. می بینید که یک قسمت زرد رنگ در نزدیکی مرکز به سمت کمی به سمت راست وجود دارد. در اینجاست که احتمال مشترک Pr (x ، y) بیشترین است ، به این معنی که یک جفت خاص x و y احتمال وقوع یک رویداد خاص را بیشتر می کند.
همچنین می توانید انواع مختلفی از آنها را مشاهده کنید نمونه هایی از تجسم در وب سایت دکتر سیمون پرنس که در آن اسلایدهای زیادی وجود دارد:
http://web4.cs.ucl.ac.uk/staff/s.prince/book/02_Intro_To_Probability.pptx
طبق معمول ، در اینجا پیوند دیگری وجود دارد که به شما در درک احتمال مشترک کمک می کند:
مقدمه ای برای حاشیه سازی
خوب ، اکنون احتمال مشترک را می دانید. بیایید در مورد "حاشیه سازی" صحبت کنیم. حاشیه نشینی راهی است از احتمال مشترک به احتمال عادی که در ابتدا انجام می دادیم. فرض کنید شما فقط احتمالات مشترک دارید:

آنچه اکنون به آن علاقه داریم احتمالات فردی مانند Pr (x = 1) یا Pr (y = 0) است. چگونه می توانیم آن را از این احتمالات مشترک محاسبه کنیم؟
نکته این است که این کار بسیار آسان است. در اینجا فرمول برای موارد مداوم و مجزا آمده است:
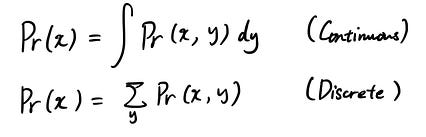
این فقط همه حالتهای ممکن را برای متغیر تصادفی که به آنها علاقه ندارید خلاصه می کند. برای درک این موضوع یک مثال را ببینید. فرض کنید می خواهید Pr (x = 0) دریافت کنید ، اما احتمالات مشترک Pr (x = 0 ، y = 0) و Pr (x = 0 ، y = 1) را دارید. برای به دست آوردن Pr (x = 0) ، با انجام موارد زیر حاشیه سازی را انجام می دهید:

بنابراین شهود پشت این محاسبه چیست؟ حاشیه نشینی سعی می کند در مورد همه موقعیت های ممکن برای وضعیت موردنظر شما فکر کند. در مورد بدست آوردن Pr (0 = x) فکر کنید. مشکل این بود که شما احتمالات مشترک Pr (x = 0 ، y = 0) و Pr (x = 0 ، y = 1) دارید. اما اگر لحظه ای به آن فکر کنید ، برای وضعیت خاصی که ما هستیمعلاقه مند به (x = 0) ، فقط دو موقعیت وجود دارد. y = 0 یا y = 1. به همین دلیل است که با جمع بندی احتمال Pr (x = 0 ، y = 0) و Pr (x = 0 ، y = 1) ، ما تمام موقعیت های احتمالی را برای Pr (0 = x) در نظر می گیریم ، بنابراین احتمال را بدست می آوریم. < /p>
بیایید یکبار دیگر به مثال باران و چتر بازگردیم. قبلاً ، ما هر ایالت را مستقل در نظر می گرفتیم ، به این معنی که یک شرط بر دیگری تأثیر نمی گذارد. فقط این بود که باران باریده یا نه و آیا شما به طور اتفاقی چتری دارید. با این حال ، در یک سناریوی دنیای واقعی ، شما رفتار بهتری خواهید داشت. منظورم این است که اگر می دانید بعد از ظهر باران می بارد ، آیا چتری با خود نمی آورید؟ اگر چنین است ، با توجه به شرایطی که ممکن است بعد از ظهر باران ببارد (فرض) ، احتمال آوردن چتر افزایش می یابد. اینجاست که احتمال شرطی مطرح می شود.
 < p> بنابراین احتمال مشروط به شکل زیر است:
< p> بنابراین احتمال مشروط به شکل زیر است: 
جایی که احتمال مشترک را بر احتمال حالتی که تصمیم خود را بر اساس آن تقسیم می کنید تقسیم می کنید. اما این معادله به چه معناست؟ عادی سازی به چه معناست؟ قبلاً توضیح دادم که احتمال مشترک شبیه نقشه کانتور در سمت چپ است. احتمال شرطی محدود کردن وضعیت با توجه به یک شرط خاص (y = y*) است. در این سناریو ، شما به همه y های احتمالی فکر نمی کنید ، بلکه فقط به y = y* خاصی تصمیم می گیرید (مانند زمانی که سعی می کنید چتر خود را بیاورید با توجه به این که می دانید ممکن است بعد از ظهر باران بیاید) ).

با توجه به y = y* ، ما به سادگی می توانیم برش را از نقشه کانتور خارج کرده و از آن به عنوان احتمال شرطی خود استفاده کنیم. اما 1 مشکل وجود دارد مساحت یک برش 1 نیست چرا؟ به یاد داشته باشید که همه احتمالات مشترک احتمالی در این زمینه باید وقتی 1 در مورد آن توضیح داده شود ، جمع شود؟ به همین دلیل است که برداشتن یک تکه به شما 1 نمی دهد زیرا شما از سایر موارد احتمالی مشترک احتمالی چشم پوشی می کنید. بنابراین ، برای تبدیل این برش به صورت PDF ، باید منطقه را عادی کنیم تا این ناحیه برش 1 شود.
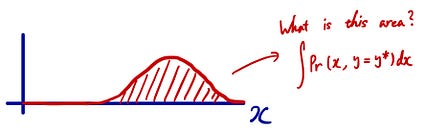
اگر حالت مداوم باشد ، مساحت با استفاده از انتگرال مانند بالا نشان داده می شود. با استفاده از این ، می توان احتمال شرطی را به این شکل محاسبه کرد:
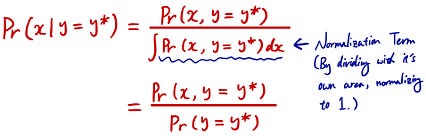
بنابراین به همین دلیل است که احتمال شرطی به شکل ساده شده به نظر می رسد:

امیدوارم ایده را گرفته باشید!
بنابراین خود فرمول بسیار آسان است. اما این فرمول به چه معناست و چگونه می توانیم این فرمول را از آنچه می دانیم بدست آوریم؟

ابتدا ، بیایید سعی کنیم خود فرمول را درک کنیم. بنابراین فرمول معروف بالا را می توان بر اساس آنچه قبلاً آموخته ایم بازنویسی کرد.

آیا این برای شما آشنا به نظر نمی رسد؟ آره! این درست مانند فرمول احتمال شرطی است که در آن ما ناحیه 1 را عادی کردیم تا بتوانیم آن را به عنوان PDF در نظر بگیریم.
بنابراین برای تجزیه قضیه بیز ، راهی برای محاسبه "پسین "با استفاده از 3 عبارت:" احتمال "،" قبلی "، و" شواهد ". از x مقدار خاصی از y
مفید است زیرا حتی اگر محاسبه عقب برای مثال دشوار باشد ، محاسبه احتمالی ، قبلی و شواهد اغلب آسان تر است. در مورد سایر شرایط نیز همینطور است.

امیدوارم فرمول را تا به حال متوجه شده باشید. بیایید ببینیم چگونه می توانیم این فرمول را از آنچه که قبلاً می دانیم استخراج کنیم.

اساساً ، ما می توانیم قضیه بیز را از تعریف احتمال شرطی استخراج کنیم. این یک مفهوم مهم است بنابراین اگر از چیزی مطمئن نیستید ، حتماً مدتی را صرف درک آن کنید!
خلاصه
اندازه گیری احتمال وقوع یک رویداد در اعداد بین 0 تا 1.
درست مانند هر متغیر دیگر ، متغیری که می تواند برای نشان دادن مقادیر احتمالی نتایج تصادفی مورد استفاده قرار می گیرد. خود RV. راهی برای نادیده گرفتن برخی متغیرهای تصادفی برای بدست آوردن احتمال با متغیرهای تصادفی کمتر. رویداد رخ داده است rred.
قاعده ای که احتمال پسین را با احتمال ، پیشین و شواهد پیوند می دهد.
امیدوارم این کمک کند! دفعه بعد می بینمت!
بینایی رایانه ای و یادگیری ماشین در PHP با استفاده از کتابخانه opencv
بینایی رایانه ای و یادگیری ماشین در PHP با استفاده از کتابخانه opencv

سلام به همگی. این مقاله مربوط به سالگرد من است. تقریباً در 7 سال من 10 مقاله (از جمله این مقاله) نوشته ام ، 8 مورد از آنها - فنی. تعداد کل بازدید همه مقالات حدود نیم میلیون است. من مشارکت اصلی را در دو مبحث انجام داده ام: PHP و مدیریت سرور. من دوست دارم در محل اتصال این دو حوزه کار کنم ، اما دامنه علایق من بسیار گسترده تر است. مانند بسیاری از توسعه دهندگان ، من اغلب از نتایج کار شخص دیگری (مقالات در رسانه ، کد در github و غیره) استفاده می کنم ، بنابراین همیشه خوشحالم که نتایج خود را در پاسخ با جامعه به اشتراک بگذارم. نوشتن مقاله نه تنها بازگشت بدهی به جامعه است ، بلکه به شما امکان می دهد افراد همفکر خود را بیابید ، نظرات خود را از متخصصان در زمینه ای محدود دریافت کنید و دانش خود را در زمینه مورد بررسی بیشتر عمیق کنید. در واقع این مقاله درباره یکی از این لحظات است. در آن من آنچه را که تقریباً تمام وقت آزاد خود را در شش ماه گذشته انجام می دادم شرح می دهم. به جز آن لحظاتی که برنامه های تلویزیونی را تماشا می کردم یا بازی می کردم.
در حال حاضر ، "یادگیری ماشین" بسیار سریع در حال توسعه است ، قبلاً مقالات زیادی از جمله مقاله های متوسط و تقریباً همه توسعه دهندگان را نوشته است. دوست دارند از آن در وظایف کاری و پروژه های خانگی خود استفاده کنند ، اما از کجا شروع کنیم و از چه چیزی استفاده کنیم همیشه قابل درک نیست. اکثر مقالات برای مبتدیان مجموعه ای از ادبیات را ارائه می دهند ، که در مورد خواندن آنها زندگی کافی وجود ندارد ، دوره های "ارزان" و غیره. به طور مرتب مقالات جدیدی ظاهر می شود که در آنها رویکردهای جدید برای حل یک مشکل خاص شرح داده شده است. در github می توانید پیاده سازی روشی را که در مقالات توضیح داده شده است بیابید. به عنوان زبانهای برنامه نویسی بیشتر از موارد زیر استفاده می شود: c /c ++ ، python 2/3 ، lua و matlab و به عنوان چارچوب: caffe ، tensorflow ، torch. تقسیم بندی زیاد در زبان ها و چارچوب های برنامه نویسی روش پیدا کردن آنچه شما نیاز دارید و ادغام آن در پروژه را بسیار پیچیده می کند.
برای کاهش این همه آشفتگی در opencv یک ماژول dnn اضافه شده است که به شما امکان می دهد از مدل آموزش داده شده در چارچوب های اساسی استفاده کنید. من به شما نشان می دهم که چگونه می توان از این ماژول از php استفاده کرد.
جرمی هوارد (خالق دوره عملی رایگان "یادگیری ماشین برای برنامه نویسان") معتقد است که اکنون بین یادگیری ماشین و یادگیری یک آستانه بزرگ وجود دارد. هوارد می گوید برای شروع یادگیری ماشینی یک سال تجربه برنامه نویسی کافی است. من کاملاً با او موافقم و امیدوارم مقاله من به کاهش آستانه ورود به opencv برای توسعه دهندگان php که با یادگیری ماشین آشنایی کمی دارند و هنوز مطمئن نیستند که آیا اصلاً می خواهند این کار را انجام دهند یا خیر ، کمک کند. سعی کنید تمام نقاطی را که برای آنها ساعت ها و روزها صرف کرده ام توصیف کنید ، بنابراین لازم نیست بیش از یک دقیقه برای این کار وقت بگذارید.
 لوگوی پروژه php-opencv
لوگوی پروژه php-opencv من در حال نوشتن بودمیک ماژول php-opencv توسط خودم با استفاده از SWIG و زمان زیادی را صرف آن کردم ، اما من به چیزی نرسیدم. همه چیز از این جهت پیچیده بود که من c /c ++ نمی دانستم و برنامه های افزودنی برای php 7 ننوشته بودم. متأسفانه اکثر مطالب موجود در اینترنت برای برنامه های افزودنی php در php 5 نوشته شده است ، بنابراین مجبور شدم اطلاعات را جمع آوری کنم کمی ، و مشکلات را به تنهایی حل کنم.
سپس من کتابخانه php-opencv را در فضای github پیدا کردم ، این یک ماژول برای php7 است که به روش های opencv تماس می گیرد. چندین شب طول کشید تا نمونه ها را گردآوری ، نصب و اجرا کنم. من سعی کردم ویژگی های مختلف این ماژول را امتحان کنم ، اما برخی از روشها را نداشتم ، خودم آنها را اضافه کردم ، یک درخواست pull ایجاد کردم و نویسنده کتابخانه قبول کرد. بعداً ، ویژگی های بیشتری اضافه کردم.
نحوه بارگذاری تصویر به این شکل است:
هنگام خواندن یک تصویر با php (همچنین مانند c ++) ، اطلاعات در شی Mat (ماتریس) ذخیره می شوند. در php ، آنالوگ آن یک آرایه چند بعدی است ، اما بر خلاف یک آرایه چند بعدی ، این شی اجازه می دهد تا دستکاری های سریع مختلفی انجام شود ، به عنوان مثال ، تقسیم همه عناصر بر یک عدد. در پایتون ، هنگامی که تصویر بارگیری می شود ، شیء numpy بازگردانده می شود.
مراقب باشید ، میراث! این اتفاق افتاد به طوری که imread (در php ، c ++ و pyton) تصویر را نه در قالب RGB ، بلکه در BGR بارگذاری می کند. بنابراین ، در مثالهای opencv ، اغلب می توانید روش تبدیل BGR -> RGB و بالعکس را مشاهده کنید.
تشخیص چهره
اولین چیزی که سعی کردم این عملکرد بود. برای آن در opencv یک کلاس CascadeClassifier وجود دارد که می تواند از پیش مدل در قالب xml استفاده کند. قبل از یافتن چهره ، توصیه می شود تصویر را به فرمت سیاه و سفید تبدیل کنید.
کد نمونه کامل
نتیجه:

همانطور که در مثال مشاهده می شود ، هیچ مشکلی در یافتن صورت حتی در عکس در آرایش زامبی وجود ندارد. نقاط نیز در یافتن شخص دخالت نمی کنند. اگر می خواهیم بدانیم چه کسانی در عکس حضور دارند ، ابتدا باید مدل را با استفاده از روش قطار آموزش دهیم ، دو پارامتر لازم است: آرایه ای از تصاویر صورت و آرایه ای از برچسب های عددی برای این تصاویر. سپس می توانید روش پیش بینی را در تصویر آزمایش (صورت) فراخوانی کرده و برچسب عددی را که با آن مطابقت دارد دریافت کنید.
کد نمونه کامل
مجموعه داده ها:


نتیجه:

وقتی کار با LBPHFaceRecognizer را شروع کردم ، توانایی ذخیره /بارگذاری /به روزرسانی مدل نهایی را نداشت. در واقع اولین درخواست کشش من این روشها را اضافه کرد: نوشتن /خواندن /بروزرسانی. < /p>
علائم چهره/نقاط دیدنی
وقتی شروع به آشنایی با opencv کردم ، اغلب با عکس هایی از افراد برخورد می کردم ، جایی که نقاط چشم ، بینی ، لب ها و غیره را مشخص می کرد. می خواستم این آزمایش را خودم تکرار کنم ، اما در نسخه opencv برای پایتون اجرا نشد. یک شب طول کشید تا پشتیبانی FacemarkLBF را به php اضافه کنم و یک بولت بک دوم ارسال کنم. همه به سادگی کار می کنند ، ما پیش مدل را بارگذاری می کنیم ، آرایه ای از چهره ها را تغذیه می کنیم ، برای هر فرد آرایه ای از امتیاز دریافت می کنیم.
کد نمونه کامل
نتیجه:

همانطور که از مثال مشاهده می شود ، آرایش یک زامبی می تواند یافتن نقاط روی صورت را مشکل کند. نقاط همچنین می توانند در یافتن چهره تداخل ایجاد کنند. روشنایی نیز بر آن تأثیر می گذارد. در این مورد ، اجسام خارجی در دهان (توت فرنگی ، سیگار و غیره) ممکن است تداخلی نداشته باشند. مقاله Deep Learning ، اکنون در OpenCV. بدون تردید ، تصمیم گرفتم امکان استفاده از مدلهای از پیش آموزش دیده را که در اینترنت زیاد است ، به php-opencv اضافه کنم. بارگیری مدل های کافه چندان دشوار نبود ، اگرچه بعداً زمان زیادی را صرف کردم تا نحوه کار با ماتریس های چند بعدی را یاد بگیرم و با مدلهای caffe /torch /tensorflow بدون استفاده از opencv کار کنم. < /p>
تشخیص چهره با استفاده از ماژول dnn
بنابراین ، opencv به شما امکان می دهد مدل های از پیش آموزش دیده را در Caffe با استفاده از عملکرد readNetFromCaffe بارگذاری کنید. این دو پارامتر را می طلبد - مسیرهای .prototxt و .caffemodel. در فایل نمونه اولیه توضیحات مدل ، و در مدل کافه-وزنهای محاسبه شده در طول آموزش مدل وجود دارد. در اینجا نمونه ای از شروع یک فایل اولیه است:
این قطعه فایل توضیح می دهد که انتظار می رود یک ماتریس 4 بعدی 1x3x300x300 ورودی را وارد کند. در توضیح مدلها ، معمولاً آنچه در این قالب انتظار می رود بیان شده است ، اما در بیشتر موارد به این معنی است که انتظار می رود تصویر RGB (3 کانال) با اندازه 300x300 وارد شود. با بارگیری یک تصویر RGB با ابعاد 300x300 با عملکرد imread ، ما ماتریسی از 300x300x3 دریافت می کنیم. برای آوردن ماتریس 300x300x3 به فرم 1x3x300x300 در opencv یک تابع blobFromImage وجود دارد. پس از آن ، ما فقط می توانیم با استفاده از روش setInput blob را روی ورودی شبکه اعمال کرده و متد forward را فراخوانی کنیم ، که نتیجه نهایی را به ما باز می گرداند.
در این حالت ، نتیجه یک ماتریس 1x1x200x7 است ، یعنی 200 آرایه از هر 7 عنصر. در یک عکس با چهار چهره ، این شبکه 200 نامزد پیدا کرد. هر کدام شبیه [، $ اعتماد ، $ startX ، $ startY ، $ endX ، $ endY] هستند. عنصر $ اطمینان مسئول "اطمینان" است ، یعنی پس از آن احتمال پیش بینیخوب است ، به عنوان مثال 0.75. عناصر زیر مختص مختصات مستطیل با صورت هستند. در این مثال ، تنها 3 نفر با اطمینان بیش از 50 found و 197 نامزد باقی مانده اطمینان کمتر از 15 found پیدا کردند.
حجم مدل 10 مگابایت است ، کد نمونه کامل
نتیجه:

تا آنجا که ممکن است از مثال مشاهده می شود ، شبکه عصبی همیشه هنگام استفاده از آن "در پیشانی" نتایج خوبی را ایجاد نمی کند. چهره چهارمی یافت نشد ، اما اگر عکس چهارم بریده شود و به طور جداگانه به شبکه ارسال شود ، چهره پیدا می شود.
بهبود کیفیت تصاویر با استفاده از شبکه عصبی
A مدتها پیش در مورد کتابخانه waifu2x شنیدم ، که به شما امکان می دهد نویز را حذف کرده و اندازه آیکون ها /عکس ها را افزایش دهید. خود کتابخانه به زبان lua نوشته شده است ، و در زیر کاپوت از چندین مدل (برای افزایش آیکون ها ، حذف نویز عکس و غیره) آموزش داده شده در مشعل استفاده می شود. نویسنده کتابخانه این مدلها را به کافه صادر کرد و به من کمک کرد تا از opencv استفاده کنم. در نتیجه ، نمونه ای برای افزایش وضوح آیکون ها در php نوشته شد. حجم مدل 2 مگابایت است ، کد کامل مثال.
 اصلی
اصلی  نتیجه
نتیجه  بزرگنمایی تصویر بدون استفاده از شبکه عصبی
بزرگنمایی تصویر بدون استفاده از شبکه عصبی طبقه بندی تصویر
The MobileNet شبکه عصبی ، آموزش داده شده بر روی مجموعه داده ImageNet ، به شما امکان می دهد یک تصویر را طبقه بندی کنید. در کل ، می تواند 1000 کلاس را تعیین کند ، که به نظر من کافی نیست. حجم مدل 16 مگابایت است ، کد کامل نمونه.
 نتیجه: 87٪ - گربه مصری ، 4٪ - گربه تابی ، گربه بزرگ ، 2٪ - گربه ببر
نتیجه: 87٪ - گربه مصری ، 4٪ - گربه تابی ، گربه بزرگ ، 2٪ - گربه ببر API تشخیص شی Tensorflow
شبکه MobileNet SSD (آشکارساز چند شات تک شات) ، آموزش داده شده در Tensorflow بر روی مجموعه داده COCO ، نه تنها می تواند یک تصویر را طبقه بندی کند ، بلکه مناطق را نیز برمی گرداند ، اگرچه فقط می تواند 182 کلاس را تشخیص دهد. حجم مدل 19 مگابایت است ، کد کامل مثال.
 اصلی < /img>
اصلی < /img>  نتیجه
نتیجه برجسته سازی نحو و تکمیل کد
من به همراه مخزن نمونه ، فایل phpdoc.php را نیز اضافه کردم. با تشکر از آن ، Phpstorm نحو توابع ، کلاسها و روشهای آنها را برجسته می کند و همچنین با تکمیل کد کار می کند. این فایل نیازی به درج کد شما ندارد (در غیر این صورت خطایی رخ می دهد) ، کافی است آن را در پروژه خود قرار دهید. شخصاً ، زندگی را برای من آسان می کند. این فایل بیشتر توابع opencv را توصیف می کند ، اما نه همه آنها ، بنابراین درخواست های pull خوش آمدید.
نصب
ماژول dnn فقط در نسخه 3.4 در opencv ظاهر شد (قبل از آن در opencv-contribute). در اوبونتو 18.04 آخرین نسخه opencv 3.2 است. ساخت opencv از منابع حدود نیم ساعت طول می کشد ، بنابراین من بسته را تحت اوبونتو 18.04 گردآوری کردم (همچنین برای 17.10 ، حجم 25 مگابایت کار می کند) ، و همچنین بسته های php-opencv را برای php 7.2 (اوبونتو 18.04) و php 7.1 (اوبونتو 17.10) گردآوری کردم. (حجم 100 کیلوبایت) ppa ثبت شده: php-opencv ، اما هنوز به پر کردن تسلط ندارد و چیزی بهتر از بارگذاری بسته ها در github پیدا نکرده است. من همچنین یک درخواست برای ایجاد یک حساب کاربری در pecl ایجاد کردم ، اما پس از چند ماه من هنوزپاسخی دریافت نکرد بنابراین در حال حاضر نصب تحت اوبونتو 18.04 به این شکل است:
نصب این گزینه حدود 1 دقیقه به طول می انجامد. همه گزینه های نصب در اوبونتو. من همچنین یک تصویر داکر 168 مگابایتی را گردآوری کردم.
نمونه هایی با استفاده از
بارگیری: opencv-samples.git && cd php-opencv-example
در حال اجرا:
PS
مشترک شوید ، بنابراین برای اینکه مقاله های بعدی من را از دست ندهید ، یک هاسکی بگذارید تا به من انگیزه دهد تا آنها را بنویسم و در نظرات س questionsالات بنویسم ، گزینه هایی را برای آزمایش/مقاله جدید ارائه دهید.
منابع:
php- نمونه های opencv-همه نمونه های مقاله php-opencv/php-opencv-چنگال من با پشتیبانی از ماژول dnn hihozhou /php-opencv-مخزن اصلی ، بدون پشتیبانی از ماژول dnn (من pulrequest را ایجاد کردم ، اما هنوز پذیرفته نشده است). https://habr.com/post/358902/- نسخه روسی
QC-کامپیوتر کوانتومی چیست؟
QC-کامپیوتر کوانتومی چیست؟
 عکس توسط Nong Vang
عکس توسط Nong Vang Hype کنجکاوی را بر می انگیزد ، اما باعث ایجاد مزاحمت های غیر ضروری نیز می شود. گوگل ادعا می کند اولین برتری کوانتومی را با پردازنده کوانتومی Sycamore 53 کیوبیت خود که بر روی مدارهای ابررسانا ساخته شده است ، نشان داد. این امر بسیار مهم است زیرا هیچ رایانه ای مشکلی را حل نکرده است که رایانه های سنتی برای همیشه به آن نیاز دارند. گوگل ادعا می کند که ژنراتور تصادفی توصیف شده در مقاله در 200s انجام می شود ، در حالی که 10000 سال طول می کشد تا شبیه ساز ژنراتور توسط کامپیوتر کلاسیک شبیه سازی شود. این برتری کوانتومی است که جامعه تحقیقاتی به دنبال آن است. با این حال ، انتظار نداشته باشید که در ماه های آینده جهشی در محاسبات داشته باشیم. برای مشکلات جالب تر ، آنها هنوز به پیشرفت زیادی نیاز دارند.
بسیاری از مجلات به پیشرفت کوانتومی در نحوه ذخیره اطلاعات بیشتر کیوبیت ها نسبت به یک بیت دودویی که صفر یا یک است ، کمک می کنند. فرض کنید یک کیوبیت می تواند 1 میلیارد اطلاعات بیشتر از یک بیت دودویی داشته باشد ، یک دستگاه 53 کیوبیتی به سادگی معادل 6.6 گیگابایت دستگاه است. من 5 سال پیش یک لپ تاپ 16 گیگابایتی خریدم. اگر فکر می کنید محاسبات کوانتومی در مورد رمزگذاری اطلاعات بیشتر در یک "بیت" واحد است ، ما به طور کامل پتانسیل آن را به شدت از دست خواهیم داد. به جای این که به شما پاسخ 60 ثانیه ای با کلمات کلیدی بدهیم ، ما پایه لازم را ایجاد می کنیم تا بتوانیم موضوع را با عمق بیشتری کاوش کنیم. اطلاعات را به شکل 0 و 1s به نام بیت ذخیره می کند در حالی که یک کامپیوتر کوانتومی اطلاعات را در حالتهای بسیار غنی تر به نام کیوبیت رمزگذاری می کند. در حالی که یک بیت واحد دارای 2 حالت ممکن است ، یک کیوبیت می تواند در هر وضعیتی در سطح کره زیر باشد.

بنابراین ترویج رایانه های کوانتومی به عنوان راهی برای طراحی رایانه کوچکتر با ظرفیت بالاتر طبیعی به نظر می رسد. نه ، در واقع ، دانشمندان معتقد نیستند که ما به زودی یک کامپیوتر کوانتومی به اندازه یک لپ تاپ خواهیم داشت. در سال 2018 ، بزرگترین رایانه کوانتومی عمومی فقط 72 کیوبیت دارد.
اطلاعات کوانتومی در برابر اختلالات محیط آسیب پذیر است. مسائل با هم تعامل دارند. حتی پردازنده کوانتومی که کیوبیت ها را نگه می دارد کوچک است ، برای جداسازی کیوبیت ها به تجهیزات زیادی نیاز داریم.
 اصلاح شده از منبع IBM
اصلاح شده از منبع IBM برای مثال ، به کامپیوتر کوانتومی IBM که دارای 50 کیوبیت است نگاهی بیندازید.
 چپ (داخل کامپیوتر کوانتومی IBM 50 کیوبیت) راست (محفظه کامپیوتر کوانتومی)
چپ (داخل کامپیوتر کوانتومی IBM 50 کیوبیت) راست (محفظه کامپیوتر کوانتومی) برای جداسازی محیط زیست ، IBM کامپیوتر کوانتومی دارای یخچال رقیق کننده است تا پردازنده کوانتومی را تا 15 میلی درجه کلوین خنک کند. همچنین دارای کابل های زیادی است که پالس های مایکروویو را برای خواندن و دستکاری کیوبیت ها ارسال می کند. در فیزیک کوانتوم ، اندازه تجهیزات نقطه قوت آن نیست. برای دسترسی و کنترل در مقیاس کوانتومی ، ماشینها معمولاً بزرگتر می شوند تا کوچک. بنابراین "بیت در مقابل کیوبیت" بخشی از محاسبات کوانتومی است اما نه کل آن.
انگیزه
ابتدا ، ما باید انگیزه محاسبات کوانتومی را درک کنیم. در سال 1981 ، برنده جایزه نوبل ، ریچارد فاینمن ، پرسید: "ما از چه کامپیوتری برای شبیه سازی فیزیک استفاده می کنیم؟" در سخنرانی خود ،

متأسفانه ، این فرآیند انرژی زیادی مصرف می کند. باکتری های موجود در خاک آنزیم های نیتروژناز تولید می کنند تا نیتروژن را از هوا خارج کرده و آمونیاک را در دمای معمولی تولید کنند. مدتی است که دانشمندان در حال بررسی این فرآیند رفع نیتروژن هستند.
 منبع
منبع با این حال ، در حالی که رایانه های ما می توانند پتا بایت اطلاعات (1،000،000 گیگابایت) را پردازش کنند ، به ندرت تعامل شیمیایی را برای خوشه F آنزیم نیتروژناز در بالا شبیه سازی می کند. این بخش بسیار کوچکی از آنزیم است که فقط شامل چهار اتم آهن و چهار اتم گوگرد است. با افزایش تعداد اتم ها ، فعل و انفعالات به صورت تصاعدی رشد می کند و برای روش کلاسیک بسیار دشوار می شود. این مشکل یک مسئله اساسی را در رایانه های فعلی ما نشان می دهد ، چگونه می توانیم سرعت محاسبات را افزایش دهیم؟

به عنوان مثال ، AI آموزش حجم عظیمی از داده ها را پردازش می کند. ما می خواهیم تا آنجا که ممکن است پردازش داده ها را موازی کنیم. برای CPU دو هسته ای زیر ، می توانیم دو کار را همزمان انجام دهیم. اما حتی با یک پردازنده 8 هسته ای ، این برای بسیاری از مشکلات AI کافی نیست.
 برنامه ریزی وظایف در CPU دو هسته ای
برنامه ریزی وظایف در CPU دو هسته ای بنابراین ، هوش مصنوعی مدلها بر روی پردازنده های گرافیکی (به عنوان مثال ، کارت گرافیک کامپیوتر) آموزش می بینند. برای پردازنده گرافیکی پیشرفته ، بیش از 4K+ هسته وجود دارد که می توانند خطوط مشابه عملیات را روی داده های 4K+ به طور همزمان موازی کنند.
 منبع: Nvidia
منبع: Nvidia اما این استراتژی هنوز محدودیت قابل توجهی دارد. برای بسیاری از مشکلات زندگی واقعی ، پیچیدگی بصورت تصاعدی (و نه خطی) با تعداد ورودی ها افزایش می یابد.

این دلیل مسئله مقیاس پذیری مثال کود است.

اگر برای حل یک مشکل مقدار زیادی داده لازم باشد ، بد است. زیرا ممکن است برای دستکاری آنها به تعداد نمایی از عملیات نیاز داشته باشد. من آن را خلاف قوانین می دانم.
موازی سازی داده ها عملکرد را به صورت خطی بهبود می بخشد ، بنابراین این درمانی برای مشکلات با پیچیدگی نمایی نیست. ما برای شکستن نفرین به مفاهیم جدیدی نیاز داریم.
رایانه های کوانتومی چه چیزی ارائه می دهند؟ به طور خلاصه ، گرفتاری و تداخل دو پدیده کوانتومی هستند که در DNA طبیعت ادغام شده اند. کامپیوترهای کوانتومی به آنها ارزان قیمت می دهند. ما همچنین می توانیم مقدار نمایی از اطلاعات را در کیوبیت ها با استفاده از برهم نهی رمزگذاری کرده و برهم نهی به طور موازی ، به جای یک داده در یک زمان ، دستکاری کنیم. این موازی سازی کوانتومی به ما امکان می دهد برخی از مسائل را سریعتر از الگوریتم های کلاسیک موجود حل کنیم. مهمتر از همه ، کاربرد رایانه های کوانتومی تنها به مشکلات دینامیک کوانتومی محدود نمی شود. راه حل هایی را در زمینه هایی ارائه می دهد که قبلاً تصور می شد بسیار پیچیده است. به عنوان مثال ، الگوریتم Shor برای شکستن رمزگذاری که معمولاً برای اینترنت استفاده می شود و یکی از اصلی ترین آنها محسوب می شود ، طراحی شده استنامزد در نشان دادن برتری کوانتومی بر محاسبات کلاسیک.
 < p> به عنوان پیش نمایش ، یک سیستم 64 کیوبیتی دارای
< p> به عنوان پیش نمایش ، یک سیستم 64 کیوبیتی دارای 
ضرایبی که می توانیم اطلاعات را قبلاً رمزگذاری و دستکاری کنیم. موازی سازی کوانتومی به ما اجازه می دهد تا همه آنها را همزمان در ارائه محاسبات موازی دستکاری کنیم. به نظر می رسد جادویی است اما متأسفانه طبیعت باعث افزایش سرعت می شود. ما نمی توانیم مستقیماً به این ضرایب دسترسی پیدا کنیم. ما از طریق اندازه گیری به اطلاعات دسترسی داریم. با این حال ، حالت سقوط شده را باز می گرداند اما ضریب را نشان نمی دهد. این کار الگوریتم های کارآمد را بسیار سخت می کند.
 سیستم 3 کیوبیتی
سیستم 3 کیوبیتی برای درک عمیق تر آن ، باید مقداری از دانش مکانیک کوانتومی را بدانیم.
چرخش
با خیال راحت این قسمت را با سرعتی که دوست دارید مرور کنید. اما درک ضد شهود مکانیک کوانتومی سرگرم کننده است.
بسیاری از ذرات و اتم ها رفتار مغناطیسی را پردازش می کنند و می توانند در زیر میدان مغناطیسی منحرف شوند. به عنوان مثال ، وقتی اتم های هیدروژن را بین دو آهن ربا شلیک می کنیم ، مسیر آن تغییر می کند.
 منبع : Wikipedia
منبع : Wikipedia در مثال زیر ، ما ذرات را به سمت صفحه شلیک می کنیم.

اگر بر این باوریم که چرخش مانند آهن ربا رفتار می کند ، با مشاهده مسیر و انحراف آن ، می توانیم چرخش ذرات را تعیین کنیم ، مانند پیکان داخل دایره زیر.
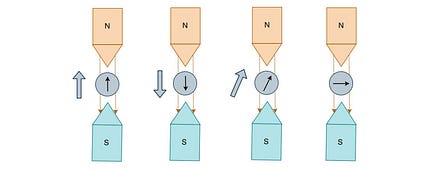
اما چرخش یک آهنربا نیست! اگر آهن ربا باشد ، اتم ها باید بسته به چرخش به نقاط مختلف روی صفحه ضربه بزنند. در عوض ، ذرات فقط در دو منطقه اصلی فرود می آیند.

(توجه داشته باشید ، تنظیمات تجربی و توضیحات برای نمایش آسان تر ساده شده است.)
چرخش دارای رفتار کوانتومی است. مسیر یا بالا یا پایین می رود ، هرگز به صورت جانبی. یعنی چرخش اندازه گیری شده فقط دارای دو حالت کوانتومی است ، یا به صورت چرخش بالا یا پایین.
 این یک چرخش بالا یا پایین است
این یک چرخش بالا یا پایین است بیایید ویژگی اسپین را کمی بیشتر بررسی کنیم. ما دو جعبه سیاه داریم که برای اندازه گیری چرخش تنظیم شده اند. در کادر اول ، چرخش رو به بالا را اندازه گیری می کنیم. ما آزمایش را طوری تنظیم کردیم که تمام ذرات خروجی در سمت راست دارای چرخش بالا و خروجی در پایین دارای چرخش پایین است. ذرات چرخش بالا را در جعبه دوم تغذیه می کنیم تا دوباره چرخش بالا را اندازه گیری کنیم. همانطور که انتظار می رفت ، 100٪ ذرات در سمت راست خارج می شوند. چرخش رو به بالا به عنوان یک چرخش بالا اندازه گیری می شود. img>
ما آزمایش را تکرار می کنیم مگر اینکه جهت آهنربا را در کادر دوم 180 درجه بچرخانیم تا چرخش رو به پایین اندازه گیری شود.

بدون هیچ شگفتی ، همه ذرات در پایین خارج می شوند. بنابراین حالتهای چرخش به بالا و چرخش منحصر به فرد یکدیگر هستند.

اکنون آخرین آزمایش را تنظیم می کنیم. در جعبه دوم و چهارم زیر ، آهنربا را در جهت عقربه های ساعت 90 درجه می چرخانیم. ما این اندازه گیری را چرخش مناسب می نامیم. جالب اینجاست که این راه اندازی با شگفتی های زیادی همراه است!

تمام ذرات خارج شده در جعبه اول دارای چرخش بالا هستند. بنابراین اندازه گیری چرخش برای جعبه 2 چیست؟ پاسخ آزمایشی این است که نیمی از ذرات به سمت راست و نیمی از ذرات به پایین خارج می شوند. با آنچه آهن ربا های کلاسیک پیش بینی می کنند متفاوت است. در مکانیک کلاسیک ، هیچ یک از آنها نباید چرخش مناسب داشته باشند. شگفتی دوم نصف استذرات به سمت راست و نیمه از پایین مجدداً در جعبه چهارم خارج می شوند. اما آیا همه ذرات چرخش پایین در جعبه 1 را از قبل فیلتر می کنیم؟ بنابراین چرا نیمی از آنها در حال چرخش پایین هستند؟
سعی کنید از شهود برای توضیح آن استفاده نکنید. شهود از تجربیات گذشته ایجاد شده است و اکثر مردم هرگز اشیاء را در مقیاس کوانتومی مشاهده نمی کنند.
بنابراین بگذارید با نظریه توطئه در مورد آنچه در حال رخ دادن است شروع کنیم. ایلان ماسک معتقد است که ما در دنیای شبیه سازی زندگی می کنیم. بنابراین اجازه دهید با این مفهوم شروع کنیم. ما در دنیای کامپیوتر زندگی می کنیم. همه اشیاء در صورت درخواست ایجاد می شوند. این بدان معناست که کامپیوتر یک شیء را تنها در صورت مشاهده آن ارائه می دهد. وقتی از خانه خارج می شوید ، مردی را در خیابان می بینید. رایانه یک برگه از گزینه های احتمالی با احتمالات مربوطه بیرون می آورد. به عنوان مثال ، 15 درصد احتمال دارد که مرد چشم سبز داشته باشد و 35 درصد احتمال دارد که چشم های قهوه ای داشته باشد و غیره ... بنابراین وقتی به صورت او نگاه می کنید ، کامپیوتر قطعه قطعه می کند و تعیین می کند که در نهایت با توجه به به تاس ها
اما اجازه دهید نظر علمی ، یعنی تفسیر کپنهاگ را بدست آوریم. اجازه دهید مستقیماً از ویکی پدیا نقل قول کنم.

اما هنگامی که چرخش اندازه گیری می شود ، طبیعت تصمیم می گیرد و وضعیت خود را بر اساس مقدار دامنه α در چرخش بالا یا پایین تنظیم می کند. بنابراین اندازه گیری ها حالت ها را تغییر می دهند. در مکانیک کلاسیک ، مشاهده ما باید به اندازه کافی ملایم باشد بنابراین نباید بر وضعیت ذرات تأثیر بگذارد. در مکانیک کوانتومی ، اندازه گیری ها روی هم قرار می گیرند تا یکی از حالت های ممکن مشاهده شده وجود داشته باشد. این قانون دینامیک کوانتومی است. به طور طبیعی ، ممکن است بپرسید چرا ما این قانون را داریم. پاسخ شخصی من این است که یا به عنوان یک قاعده اساسی در طبیعت (غیرقابل انکار) کدگذاری شده است یا فیزیک عمیق تری وجود دارد که باید کشف شود. در واقع ، توضیحات رقابتی از جمله تفسیر جهان های متعدد (معروف به جهان موازی) وجود دارد. این یک داستان علمی تخیلی نیست. این مورد توجه دانشمندان تحسین شده از جمله استفان هاوکینگ قرار می گیرد.
مفهوم برهم نهی هسته اصلی مکانیک کوانتومی است. معمولاً توضیح داده می شود که پین به طور همزمان در بالا و پایین قرار دارد. اما من در برابر این وسوسه مقاومت خواهم کرد زیرا ما به سادگی نظریه را با شهود خود تطبیق می دهیم. در فیلم Men in Black II ، تامی جونز به کار داخلی دستگاه مرتب سازی حروف اهمیتی نمی دهد. او هرگز آن را باز نمی کند اما دستگاه به خوبی به او سرویس می دهد.
ما کلید افشای آن را نداریمراز کوانتومی هنوز بسیار محتمل است که طبیعت در را مهر و موم کرده باشد و از بیرون قابل دسترسی نباشد. یا ما منتظر هستیم که دانشمند هوشمند دیگری کلید را به ما بدهد. اما هرگز از تامی جونز در استفاده از مرتب کننده برای پردازش حروف جلوگیری نمی کند. بنابراین تمرکز ما بر این است که یک مدل ریاضی برای ترکیب اضافی بسازیم و از آن برای توسعه یک کامپیوتر کوانتومی استفاده کنیم. اما ما این کار را با ایمان کور انجام نمی دهیم. مدل ریاضی با آزمایشات مطابقت دارد. تا زمانی که جعبه را به خوبی مدل می کند ، کمتر نگران این خواهم بود که دقیقاً در داخل چه اتفاقی می افتد.
هشدار
اما قبل از توضیح محاسبات کوانتومی با جزئیات ، یک چیز وجود دارد که باید انجام دهم. پیشاپیش ما در حال توسعه یک کامپیوتر کوانتومی برای جایگزینی یک کامپیوتر کلاسیک نیستیم. محاسبات کوانتومی به الگوریتم های جدیدی نیاز دارد. ما نمی توانیم برنامه های موجود C ++ را دوباره کامپایل کنیم.
یک تصور غلط بزرگ این است که یک کامپیوتر کوانتومی سریعتر از یک کامپیوتر کلاسیک همه مشکلات را حل می کند. این یک محصول جانبی بیش از حد فن آوری است. این انتظار غیرواقعی در مطالعه محدودیت های آن به ما صدمه می زند و ما را به مسیر اشتباه می رساند. بدتر از آن ، این امر مانع کشف پتانسیل واقعی آن می شود. مشکلات زیادی وجود دارد که محاسبه کوانتومی مقرون به صرفه نیست ، یا به زودی مزیت عملکردی را نشان نمی دهند. رایانه های کوانتومی و رایانه های کلاسیک در کنار هم قرار گرفته و مکمل یکدیگر هستند. الگوریتم های کوانتومی محدودیت هایی دارند. به عنوان مثال ، بعید است که آنها سرعت تصاعدی را برای مشکلات کامل NP ارائه دهند-یک افسانه رایج در محاسبات کوانتومی.
 منبع: Lev S. Bishop
منبع: Lev S. Bishop خوشبختانه ، برخی از مشکلات پیچیده متعلق به کلاسی به نام BQP (زمان چند جمله ای کوانتومی خطای محدود) است-این احتمال خوب وجود دارد که ما می تواند راه حل را در زمان چند جمله ای پیدا کند ، اما هیچ تضمینی وجود ندارد. Factorization ، مهمترین قسمت در شکستن رمزگذاری RSA ، متعلق به BQP است. بنابراین ، موفقیت محاسبات کوانتومی به احتمال زیاد بستگی به موارد دیگری دارد که به BQP تعلق دارد.
رایانه های کلاسیک همچنین رقیبی سرسخت برای کامپیوترهای کوانتومی هستند. ما می دانیم که محاسبات کوانتومی پتانسیل بالایی دارد ، اما درک عمیقی در مورد آنچه که محاسبات کلاسیک نمی تواند ارائه دهد ، نداریم. دانشمندان از الگوریتم های کوانتومی یاد می گیرند و تکنیک های ریاضی را برای بهبود الگوریتم های کلاسیک معرفی می کنند. در حقیقت ، اثبات این امر ممکن است که هیچ حالت درهم تنیدگی ایجاد نمی شود ، الگوریتم های کلاسیک می توانند به اندازه الگوریتم های کوانتومی کارآمد باشند. اما ما نمی دانیم که چرا پیچیدگی اینقدر مهم است و بنابراین هنوز نمی توانیم پتانسیل کامل خود را آشکار کنیم. تاکنون ما یک کامپیوتر کوانتومی با کیوبیت کافی برای غلبه بر رایانه های کلاسیک نساخته ایم. به برای بررسی بیشتر ، ما نیاز به درک روبرو و کیوبیت ها داریم. ما برخی از ریاضیات را در مورد آن توسعه می دهیم ، اما به محض آشنایی با علامت گذاری ، بسیار ساده خواهد بود. در واقع ، بسیاری از مردم آن را آنقدر زیبا می دانند که راه ساده تری برای درک همه این رفتارهای غیر شهودی ارائه می دهد.
در اینجا رمزگذاری کنیمشاخص کل مجموعه است: