رایانه BASIC مبتنی بر آردوینو خود را تنها با چند دلار بسازید
رایانه BASIC مبتنی بر آردوینو خود را تنها با چند دلار بسازید
زبان برنامه نویسی BASIC (کد دستورالعمل نمادین همه کاره مبتدی) اکنون بیش از 50 سال عمر دارد. اگر از رایانه خانگی دهه 70 یا 80 استفاده کرده اید ، مطمئناً در معرض آن قرار گرفته اید ، زیرا اکثر رایانه های آن دوران با مترجم BASIC نصب شده بودند. محبوبیت آن در دهه 90 کاهش یافت ، اما این بدان معنا نیست که شما نمی توانید رایانه اصلی خود را بسازید تا امروز لذت های زبان را تجربه کنید.

Rob Cai یک آموزش فوق العاده در مورد چگونگی ساخت رایانه BASIC مبتنی بر آردوینو به اشتراک گذاشته است و فقط برای شما هزینه دارد چند دلار تنها چیزی که نیاز دارید یک جفت آردوینو ، یک درگاه PS2 برای صفحه کلید و یک درگاه VGA برای خروجی ویدئو به یک مانیتور است. شما به آردوینوهایی نیاز دارید که از میکروکنترلر ATmega328 استفاده می کنند ، اما خوشبختانه این دستگاه هم در Uno در همه جا و هم در نانو کوچک و ارزان وجود دارد.

دو آردوینو مورد نیاز است ، زیرا یکی به عنوان رایانه خود TinyBASIC Plus را اجرا می کند ، در حالی که دیگری وظیفه فشرده تولید خروجی ویدئوی VGA را بر عهده دارد. این خروجی ویدئو رنگی است ، که ارتقاء خوبی از پیاده سازی های رایج سیاه و سفید است. تنها کاری که باید انجام دهید این است که یک مانیتور و صفحه کلید را وصل کنید ، و می توانید مستقیماً در مترجم BASIC بوت کنید و برنامه نویسی را شروع کنید!

طراحی برای انسان و نه برای کامپیوتر
طراحی برای انسان و نه برای کامپیوتر

طراحی باید برای برآوردن نیازهای کاربران ایجاد شود. اولین قدم از یک فرآیند طراحی ، درک الزامات و کاربران است - برای ملاقات با کاربر و درک رفتار او ، محیط کار او ، دوست داشتن و دوست نداشتن او و طرز فکر او.
گاهی اوقات بسیار وسوسه کننده است بدون انجام تحقیقات در مورد کاربر ، وارد مرحله طراحی شوید. این می تواند برای محصول خطرناک باشد و تجربه آن را از بین ببرد.
یک رویکرد خوب در فرایند طراحی کاربرمحور این است که بر اساس اطلاعات کاربر از جمله بیوگرافی ، مهارت ها ، رفتارها و تخصص وی ، شخصیت های کاربر ایجاد کنید. هنگام طراحی محصول ، بارها به این شخصیت مراجعه کنید. این به شما کمک می کند تا مسیر درست را دنبال کنید.
یک طراح یک کاربر نیست ، و او نمی تواند باشد. او هنگام تصمیم گیری در طراحی نباید به پیش فرض ها و دوست داشتن/دوست نداشتن خود تکیه کند.
نقش طراح UX ارتباط زیادی با روانشناسی انسان دارد. او باید روان انسان را بفهمد تا جریانات و تعاملات کاربران را توسعه دهد.
او باید بتواند هنگام حرکت در طراحی ، اقدامات کاربران را پیش بینی کند. سپس او می تواند این اطلاعات را در کاغذها و صفحه ها قرار دهد.
همه اینها را می توان بر اساس دانش طراح در مورد رفتار انسان به طور کلی و به طور خاص در مورد کاربران خود انجام داد.
با تشکر از خواندن شما. < /p>
برای مقالات مرتبط بیشتر در UX World مشترک شوید.
اگر س questionsالی دارید ، اینجا تماس بگیرید: فیس بوک | YouTube | توییتر | اینستاگرام | Linkedin
بیشتر از کجا آمده است
این داستان در Noteworthy منتشر شده است ، جایی که روزانه هزاران نفر می آیند تا با افراد و ایده های شکل دهنده محصولات مورد علاقه ما آشنا شوند.
< p> برای مشاهده داستانهای بیشتر ویژه تیم مجله ، نشریه ما را دنبال کنید.آموزش پایتون OpenCV-بینایی رایانه ای با OpenCV در پایتون
آموزش پایتون OpenCV-بینایی رایانه ای با OpenCV در پایتون
 OpenCV آموزش - Edureka
OpenCV آموزش - Edureka در این مقاله آموزشی OpenCV Python ، ما جنبه های مختلف دید کامپیوتر را با استفاده از OpenCV در پایتون پوشش خواهیم داد. OpenCV برای مدت طولانی بخشی حیاتی در توسعه نرم افزار بوده است. یادگیری OpenCV یک سرمایه خوب برای توسعه دهنده برای بهبود جنبه های برنامه نویسی است و همچنین در ایجاد حرفه توسعه نرم افزار کمک می کند.
ما مفاهیم زیر را بررسی می کنیم:
چشم انداز رایانه ای چیست؟
برای ساده سازی پاسخ به این مورد - اجازه دهید سناریویی را در نظر بگیریم.
همه ما از فیس بوک استفاده کنید ، درست است؟ بگذارید بگوییم شما و دوستانتان به تعطیلات رفته اید و شما روی تعداد زیادی عکس کلیک کرده اید و می خواهید آنها را در فیس بوک بارگذاری کنید و این کار را انجام داده اید. اما حالا ، آیا پیدا کردن چهره دوستان و برچسب گذاری آنها در تک تک عکس ها اینقدر زمان نمی برد؟ خوب ، فیس بوک به اندازه کافی هوشمند است تا افراد را برای شما تگ کند.
بنابراین ، فکر می کنید ویژگی برچسب خودکار چگونه کار می کند؟ به زبان ساده ، روی بینایی رایانه کار می کند.
بینایی کامپیوتری یک حوزه بین رشته ای است که به نحوه ایجاد رایانه برای درک سطح بالا از تصاویر یا فیلم های دیجیتالی می پردازد.
ایده در اینجا این است که وظایفی را که سیستم های بصری انسان می توانند انجام دهند ، خودکار کند. بنابراین ، یک کامپیوتر باید بتواند اشیایی مانند صورت یک انسان یا چراغ چراغ یا حتی یک مجسمه را تشخیص دهد.
چگونه یک کامپیوتر یک تصویر را می خواند؟
تصویر زیر را در نظر بگیرید:

ما می توانیم بفهمیم این تصویری از خط افق نیویورک است. اما آیا یک کامپیوتر می تواند همه اینها را به تنهایی پیدا کند؟ پاسخ منفی است!
رایانه هر تصویری را در محدوده مقادیر بین 0 تا 255 می خواند.
برای هر تصویر رنگی ، 3 کانال اصلی وجود دارد - قرمز ، سبز و آبی به نحوه عملکرد آن بسیار ساده است.
برای هر رنگ اصلی یک ماتریس تشکیل می شود و بعداً این ماتریس ها ترکیب می شوند و مقدار Pixel را برای رنگهای R ، G ، B ارائه می کنند.
هر کدام عنصر ماتریس داده های مربوط به شدت روشنایی پیکسل را ارائه می دهد.
تصویر زیر را در نظر بگیرید:

همانطور که نشان داده شده است ، اندازه تصویر در اینجا می تواند B*A x 3 محاسبه شود.
توجه: برای یک تصویر سیاه و سفید ، فقط یک کانال واحد وجود دارد.
در ادامه این مقاله ، بیایید ببینیم که OpenCV در واقع چیست.
OpenCV چیست؟
< p> OpenCV یک کتابخانه پایتون است که برای حل مشکلات بینایی کامپیوتر طراحی شده است. OpenCV در ابتدا در سال 1999 توسط اینتل توسعه یافت اما بعداً توسط Willow Garage پشتیبانی شد.OpenCV از طیف گسترده ای از زبان های برنامه نویسی مانند C ++ ، Python ، Java و غیره پشتیبانی می کند. و MacOS.
OpenCV پایتون چیزی نیست جز یک کلاس بسته بندی برای کتابخانه اصلی C ++ که با پایتون استفاده می شود. با استفاده از این ، همه ساختارهای آرایه OpenCV به/از آرایه های NumPy تبدیل می شوند.
این امر ادغام آن با سایر کتابخانه هایی که از NumPy استفاده می کنند را آسان می کند. برایبه عنوان مثال ، کتابخانه هایی مانند SciPy و Matplotlib.
در ادامه این مقاله ، اجازه دهید برخی از عملیات اساسی را که می توانیم با OpenCV انجام دهیم ، بررسی کنیم.
عملیات اساسی با OpenCV؟ < /h1>
اجازه دهید مفاهیم مختلفی را از بارگذاری تصاویر گرفته تا تغییر اندازه آنها و غیره بررسی کنیم.
بارگیری یک تصویر با استفاده از OpenCV:
وارد کردن cv2
# تصویر رنگی
Img = cv2.imread ("Penguins.jpg" ، 1)
# سیاه و سفید (مقیاس خاکستری)
Img_1 = cv2.imread ("Penguins.jpg" ، 0)) همانطور که در قطعه کد بالا مشاهده شد ، اولین نیاز وارد کردن ماژول OpenCV است.
بعداً ما می تواند تصویر را با استفاده از ماژول imread بخواند. 1 در پارامترها نشان می دهد که یک تصویر رنگی است. اگر پارامتر به جای 1 ، 0 باشد ، به این معنی است که تصویر وارد شده یک تصویر سیاه و سفید است. نام تصویر در اینجا "پنگوئن ها" است. کاملاً ساده ، درست است؟
شکل تصویر/وضوح تصویر:
ما می توانیم از تابع فرعی شکل برای چاپ شکل تصویر استفاده کنیم. به زیر مراجعه کنید.
وارد کردن cv2
# سیاه و سفید (مقیاس خاکستری)
Img = cv2.imread ("Penguins.jpg"، 0)
Print (img.shape) منظور از شکل تصویر ، شکل آرایه NumPy است. همانطور که در اجرای کد مشاهده می کنید ، ماتریس شامل 768 ردیف و 1024 ستون است.
نمایش تصویر:
نمایش تصویر با استفاده از OpenCV بسیار ساده و سرراست است. به زیر مراجعه کنید.
وارد کردن cv2
# سیاه و سفید (مقیاس خاکستری)
Img = cv2.imread ("Penguins.jpg"، 0)
cv2.imshow ("پنگوئن ها" ، img)
cv2.waitKey (0)
# cv2.waitKey (2000)
cv2.destroyAllWindows () همانطور که مشاهده می کنید ، ابتدا تصویر را با استفاده از imread وارد می کنیم. ما برای نمایش تصاویر به یک خروجی پنجره نیاز داریم ، درست است؟
ما از تابع imshow برای نمایش تصویر با باز کردن یک پنجره استفاده می کنیم. 2 پارامتر برای تابع imshow وجود دارد که نام پنجره و تصویر مورد نظر است.
بعداً منتظر یک رویداد کاربر هستیم. waitKey تا زمانی که کاربر کلیدی را فشار ندهد پنجره را ثابت می کند. پارامتری که به آن منتقل می شود زمان بر حسب میلی ثانیه است.
و در نهایت ، ما از killAllWindows برای بستن پنجره بر اساس پارامتر waitForKey استفاده می کنیم.
تغییر اندازه تصویر:
< p> به طور مشابه ، تغییر اندازه تصویر بسیار آسان است. در اینجا قطعه کد دیگری وجود دارد: وارد کردن cv2
# سیاه و سفید (مقیاس خاکستری)
img = cv2.imread ("Penguins.jpg"، 0)
resized_image = cv2.resize (img، (650،500))
cv2.imshow ("پنگوئن ها" ، resized_image)
cv2.waitKey (0)
cv2.destroyAllWindows () در اینجا از تابع تغییر اندازه برای تغییر اندازه تصویر به شکل دلخواه استفاده می شود. پارامتر اینجا شکل تصویر تغییر اندازه جدید است.
بعداً توجه داشته باشید که شیء تصویر از img به resized_image تغییر می کند ، زیرا شیء تصویر در حال حاضر تغییر کرده است.
بقیه کد برای کد قبلی بسیار ساده است ، درست است؟
من مطمئن هستم که شما کنجکاو هستید که به پنگوئن ها نگاه کنید ، درست است؟ این تصویری است که ما در تمام این مدت به دنبال خروجی آن بودیم!

روش دیگری برای انتقال پارامترها به تابع تغییر اندازه وجود دارد. به پایین مراجعه کنید.
Resized_image = cv2.resize (img، int (img.shape [1]/2)، int (img.shape [0]/2)))
در اینجا ، شکل تصویر جدید نصف تصویر اصلی می شود.
در ادامه این مقاله ، اجازه دهید نحوه تشخیص چهره با استفاده از OpenCV را بررسی کنیم.
تشخیص چهره با استفاده از OpenCV
این روش در ابتدا پیچیده به نظر می رسد اما بسیار آسان است. اجازه دهید کل مراحل را با شما در میان بگذارم و شما نیز همان احساس را خواهید داشت.
مرحله 1: با توجه به پیش نیازهای ما ، برای شروع به تصویر نیاز داریم. بعداً ما باید یک طبقه بندی آبشار ایجاد کنیم کهدر نهایت ویژگی های چهره را به ما می دهد.
مرحله 2: این مرحله شامل استفاده از OpenCV است که تصویر و فایل ویژگی ها را می خواند. بنابراین در این مرحله ، آرایه های NumPy در نقاط اصلی داده وجود دارد.
تنها کاری که باید انجام دهیم این است که مقادیر سطر و ستون صورت NumPy ndarray را جستجو کنیم. این آرایه با مختصات مستطیل صورت است.
مرحله 3: این مرحله نهایی شامل نمایش تصویر با کادر صورت مستطیلی است.
تصویر زیر را بررسی کنید ، در اینجا من خلاصه کرده ام 3 مرحله به شکل تصویر برای خوانایی راحت تر:
بسیار ساده ، درست است؟

ابتدا ، یک شی CascadeClassifier برای استخراج ویژگی های صورت ایجاد می کنیم ، همانطور که قبلاً توضیح داده شد. مسیر فایل XML که حاوی ویژگی های چهره است ، پارامتر اینجاست.
مرحله بعدی خواندن تصویری است که روی آن چهره وجود دارد و با استفاده از COLOR_BGR2GREY به تصویر سیاه و سفید تبدیل می شود. به دنبال آن ، مختصات تصویر را جستجو می کنیم. این کار با استفاده از deteMultiScale انجام می شود.
از چه مختصاتی می پرسید؟ این مختصات مستطیل صورت است. scaleFactor برای کاهش مقدار شکل تا 5٪ تا زمانی که صورت پیدا شود استفاده می شود. بنابراین ، در کل - هر چه مقدار کوچکتر باشد ، دقت بیشتر است.
در نهایت ، صورت روی پنجره چاپ می شود.
افزودن کادر صورت مستطیلی:
< p> این منطق بسیار ساده است - به سادگی استفاده از دستور حلقه for. تصویر زیر را ببینید.
ما تعریف روش ایجاد مستطیل با استفاده از cv2.rectangle با عبور پارامترهایی مانند شیء تصویر ، مقادیر RGB طرح کلی جعبه و عرض مستطیل.
اجازه دهید کل کد را برای تشخیص چهره بررسی کنیم: < /p>
وارد کردن cv2
# یک CascadeClassifier Object ایجاد کنید
face_cascade = cv2.CascadeClassifier ("haarcascade_frontalface_default.xml")
# خواندن تصویر همانطور که هست
img = cv2.imread ("photo.jpg")
# خواندن تصویر به عنوان تصویر مقیاس خاکستری
gray_img = cv2.cvtColor (img ، cv2.COLOR_BGR2GRAY)
# مختصات تصویر را جستجو کنید
چهره ها = face_cascade.detectMultiScale (gray_img، scaleFactor = 1.05،
حداقل همسایگان = 5)
برای x ، y ، w ، h در صورت:
img = cv2. rectangle (img، (x، y)، (x+w، y+h)، (0،255،0)، 3)
تغییر اندازه = cv2.resize (img، (int (img.shape [1]/7)، int (img.shape [0]/7)))
cv2.imshow ("خاکستری" ، تغییر اندازه)
cv2.waitKey (0)
cv2.destroyAllWindows () در ادامه این مقاله ، بیایید نحوه استفاده از OpenCV برای ضبط ویدئو با وب کم کامپیوتر را بررسی کنیم.
ضبط ویدئو با استفاده از OpenCV
< p> فیلمبرداری با استفاده از OpenCV نیز بسیار ساده است. حلقه زیر ایده بهتری به شما می دهد. آن را بررسی کنید:
تصاویر یکی خوانده می شوند ویدئوها به دلیل پردازش سریع فریم ها ایجاد می شوند که باعث حرکت تک تک تصاویر می شود.
ضبط ویدئو:
تصویر زیر را مشاهده کنید:
< img src = "https://cdn-images-1.medium.com/max/426/1*AElOdTJjCzjfnWIhKwXcYA.png">ابتدا کتابخانه OpenCV را طبق معمول وارد می کنیم. در مرحله بعد ، روشی به نام VideoCapture داریم که برای ایجاد شی VideoCapture استفاده می شود. این روش برای فعال کردن دوربین روی دستگاه کاربر استفاده می شود. پارامتر این عملکرد نشان می دهد که آیا برنامه باید از دوربین داخلی یا دوربین اضافی استفاده کند. "0" نشان دهنده دوربین داخلی استاین مورد.
و سرانجام ، از روش انتشار برای رهاسازی دوربین در چند میلی ثانیه استفاده می شود.
وقتی جلو می روید و تایپ می کنید و سعی می کنید کد فوق را اجرا کنید ، متوجه می شود که چراغ دوربین برای چند ثانیه روشن می شود و بعداً خاموش می شود. چرا این اتفاق می افتد؟
این اتفاق می افتد زیرا هیچ زمان تأخیری برای عملکرد دوربین وجود ندارد.

با نگاهی به کد بالا ، خط جدیدی به نام time.sleep (3) داریم - این باعث می شود که اسکریپت به مدت 3 ثانیه متوقف شود. توجه داشته باشید که پارامتر منتقل شده زمان در ثانیه است. بنابراین ، وقتی کد اجرا شد ، وب کم به مدت 3 ثانیه روشن می شود.
افزودن پنجره:
افزودن یک پنجره برای نمایش خروجی ویدئو بسیار ساده است و می تواند در مقایسه با روشهای مشابهی که برای تصاویر استفاده می شود. با این حال ، تغییر جزئی وجود دارد. کد زیر را بررسی کنید:

من زیبا هستم مطمئن باشید که می توانید از کد فوق جدا از یک یا دو خط بیشترین معنا را داشته باشید. آرایه قاب. /p> 
همانطور که می توانید بررسی کنید ، خروجی را دریافت کردیم به عنوان True و بخشی از آرایه قاب چاپ می شود.
اما برای شروع باید اولین فریم/تصویر ویدیو را بخوانیم ، درست است؟
برای انجام دقیق این کار ، ما ابتدا باید یک شیء فریم ایجاد کنید که تصاویر شیء VideoCapture را بخواند.
 < /img>
< /img> همانطور که در بالا مشاهده شد ، از روش imshow برای گرفتن اولین فریم ویدئو استفاده می شود.
در تمام این مدت ، ما سعی کرده ایم اولین تصویر/قاب ویدیو را به طور مستقیم ضبط کنیم ضبط ویدئو.
بنابراین چگونه می توان فیلم را به جای اولین تصویر در OpenCV ضبط کرد؟
ضبط مستقیم فیلم:
به منظور ضبط ویدیو ، ما از حلقه while استفاده خواهیم کرد. در حالی که شرایط به گونه ای است که تا زمانی که "check" درست نباشد. اگر چنین است ، Python فریم ها را نمایش می دهد.
در اینجا تصویر قطعه کد آمده است:

ما از تابع cvtColor برای تبدیل هر فریم به تصویر در مقیاس خاکستری استفاده می کنیم ، همانطور که قبلاً توضیح داده شد.
waitKey (1) اطمینان حاصل کنید که یک فریم جدید پس از هر میلی ثانیه فاصله ایجاد می کنید.
در اینجا مهم است که توجه داشته باشید که حلقه while کاملاً در حال پخش است تا به تکرار فریم ها و در نهایت نمایش فیلم کمک کند.
ماشه رویداد کاربر نیز در اینجا وجود دارد. هنگامی که کاربر کلید 'q' را فشار می دهد ، پنجره برنامه بسته می شود.
درک OpenCV بسیار آسان است ، درست است؟ من شخصاً دوست دارم که خوانایی آن چقدر خوب است و چگونه یک مبتدی می تواند کار با OpenCV را به سرعت شروع کند.
در ادامه این مقاله ، بیایید نحوه استفاده از یک مورد کاربرد جالب آشکارساز حرکت با استفاده از OpenCV را بررسی کنیم.
مورد استفاده: تشخیص حرکت با استفاده از OpenCV
بیان مشکل:
شرکتی که رفتار انسان را مطالعه می کند با شما تماس گرفته است. وظیفه ی شمااین است که به آنها یک وب کم بدهید که بتواند حرکت یا هر حرکتی را در مقابل آن تشخیص دهد. این باید یک گراف را برگرداند ، این نمودار باید شامل مدت زمانی باشد که انسان/جسم مقابل دوربین بوده است.

بنابراین ، اکنون که ما بیانیه مشکل خود را تعریف کرده ایم ، باید منطقی راه حل ایجاد کنیم تا به صورت ساختارمند به مسئله نزدیک شویم.
در نظر بگیرید نمودار زیر:

در ابتدا ، ما ذخیره می کنیم تصویر در یک قاب خاص.
مرحله بعدی شامل تبدیل تصویر به تصویر تار Gaussian است. این کار به منظور اطمینان از محاسبه تفاوت محسوس بین تصویر تار و تصویر واقعی انجام می شود.
در این مرحله ، تصویر هنوز یک شی نیست. ما یک آستانه برای حذف لکه ها مانند سایه ها و سایر صداهای موجود در تصویر تعریف می کنیم.
حاشیه های شی بعداً مشخص می شوند و همانطور که قبلاً در وبلاگ در مورد آن صحبت کردیم ، یک جعبه مستطیلی در اطراف آن اضافه می کنیم.
در نهایت ، ما زمان نمایش و خروج شی از قاب را محاسبه می کنیم.
بسیار آسان است ، درست است؟
در اینجا قطعه کد آمده است:
< img src = "https://cdn-images-1.medium.com/max/426/1*tkoLRNbYxGMYGgSHx-eZTA.png">همین اصل در اینجا نیز رعایت می شود. ابتدا بسته را وارد می کنیم و شیء VideoCapture را ایجاد می کنیم تا از ضبط ویدئو با استفاده از وب کم اطمینان حاصل کنیم.
حلقه while از طریق فریم های جداگانه ویدیو تکرار می شود. ما قاب رنگ را به یک تصویر در مقیاس خاکستری تبدیل می کنیم و بعداً این تصویر را در مقیاس خاکستری به محو گاوس تبدیل می کنیم.
ما باید اولین تصویر/قاب ویدیو را ذخیره کنیم ، درست است؟ ما فقط از عبارت if برای این منظور استفاده می کنیم.
اکنون ، اجازه دهید کمی بیشتر در کد وارد شویم:

ما از تابع absdiff برای محاسبه تفاوت بین اولین فریم رخ داده و همه فریم های دیگر استفاده می کنیم.
تابع آستانه یک مقدار آستانه ارائه می دهد ، به طوری که مقدار اختلاف کمتر از 30 را به سیاه تبدیل می کند. اگر تفاوت بیشتر از 30 باشد ، پیکسل ها را به رنگ سفید تبدیل می کند. THRESH_BINARY برای این منظور استفاده می شود.
بعداً ، از تابع findContours برای تعیین ناحیه کانتور برای تصویر خود استفاده می کنیم. و در این مرحله نیز مرزها را اضافه می کنیم.
عملکرد contourArea ، همانطور که قبلاً توضیح داده شد ، صداها و سایه ها را حذف می کند. برای ساده تر ، فقط آن قسمت را سفید نگه می دارد ، که مساحت آن بیشتر از 1000 پیکسل است ، همانطور که برای آن تعریف کرده ایم.
بعداً ، یک جعبه مستطیلی در اطراف شیء خود در قاب کار ایجاد می کنیم. .
و به دنبال آن این کد ساده وجود دارد:

همانطور که قبلاً بحث شد ، فریم هر 1 میلی ثانیه تغییر می کند و هنگامی که کاربر "q" را وارد می کند ، حلقه شکسته می شود و پنجره بسته می شود.
ما همه موارد اصلی را پوشش داده ایم. جزئیات این وبلاگ آموزش OpenCV Python. موردی که در مورد مورد استفاده ما باقی می ماند این است که ما باید زمانی را که شیء در مقابل دوربین قرار داشت محاسبه کنیم.
محاسبه زمان:

ما از DataFrame برای ذخیره مقادیر زمانی استفاده می کنیم که طی آن تشخیص و حرکت شی در فریم. اما در اینجا ، ما یک بیت پرچم داریم که به آن وضعیت می گوییم. ما از این وضعیت در استفاده می کنیمشروع ضبط صفر است زیرا شیء در ابتدا قابل مشاهده نیست.

هنگامی که شیء در شکل بالا مشخص می شود ، پرچم وضعیت را به 1 تغییر می دهیم. بسیار ساده ، درست است؟

ما قصد داریم فهرستی از وضعیت برای هر فریم اسکن شده تهیه کنید و بعداً تاریخ و زمان را با استفاده از زمان داده در یک لیست در صورت تغییر و مکان ایجاد کنید.

و مقادیر زمان را در یک DataFrame ذخیره می کنیم ، همانطور که در نمودار توضیحی بالا نشان داده شده است. ما با نوشتن DataFrame در یک فایل CSV مطابق شکل به پایان می رسانیم.
رسم نمودار تشخیص حرکت:
آخرین مرحله در مورد استفاده ما برای نمایش نتایج. ما نمودار را نشان می دهیم که حرکت را در 2 محور نشان می دهد. کد زیر را در نظر بگیرید:

برای شروع ، ما DataFrame را از فایل motion_detector.py وارد می کنیم.
مرحله بعدی شامل تبدیل زمان به فرمت رشته قابل خواندن است که قابل تجزیه است.
در نهایت ، مقادیر زمانی DataFrame رسم می شود در مرورگر با استفاده از نمودارهای بوکه.
خروجی:

امیدوارم این مقاله به شما در یادگیری تمام اصول اولیه مورد نیاز برای شروع کار با OpenCV با استفاده از پایتون کمک کند.
هنگامی که می خواهید برنامه هایی را توسعه دهید که نیاز به تشخیص تصویر دارند ، بسیار مفید خواهد بود. و اصول مشابه در حال حاضر ، شما همچنین باید بتوانید از این مفاهیم برای توسعه برنامه ها به راحتی با کمک OpenCV در پایتون استفاده کنید.
اگر مایل هستید مقالات بیشتری را در مورد پرطرفدارترین فناوری های بازار مانند هوش مصنوعی ، DevOps ، بررسی کنید. سپس می توانید به سایت رسمی Edureka مراجعه کنید.
به دنبال مقالات دیگر این سری باشید که جنبه های مختلف دیگر پایتون و علم داده را توضیح می دهد.
در ابتدا در www.edureka.co در 8 فوریه 2019 منتشر شد.
دانش آموزان Udacity با شبکه های عصبی و بینایی رایانه آزمایش می کنند
دانش آموزان Udacity با شبکه های عصبی و بینایی رایانه آزمایش می کنند

برنامه نانو درجه مهندس اتومبیل خودران Udacity دانش آموزان را ملزم می کند که تعدادی پروژه را به اتمام برسانند ، و هر پروژه نیاز به آزمایش دانش آموزان برای یافتن راه حلی کارآمد دارد.
در اینجا پنج پست توسط Udacity آورده شده است. دانش آموزان ، نحوه استفاده از آزمایش برای تکمیل پروژه های خود را بیان می کنند.
دفتر خاطرات مهندس خودروهای خودران-4
اندرو ویلکی

اندرو دارای تصاویر زیادی در این پست وبلاگ است ، از جمله صفحه گسترده ای از همه عملکردهای مختلفی که در ساختن خود استفاده کرده است طبقه بندی علائم راهنمایی و رانندگی با TensorFlow!
پیچیدگی های طبقه بندی علائم راهنمایی و رانندگی با TensorFlow
Param Aggarwal

در این پست ، پارام مراحل یافتن ترکیب مناسب پیش پردازش ، افزایش و معماری شبکه را به صورت مرحله به مرحله طی می کند. برای طبقه بندی علائم راهنمایی و رانندگی 54 معماری شبکه عصبی در کل! می خواستم گریه کنم. یک مدل پایه خطی 85 درصد به من می داد و در اینجا از جدیدترین لایه های پیچشی استفاده می کنم و نمی توانم مطابقت داشته باشم. جاناتان میچل  < p> انتشار مجدد دشوارترین و خسته کننده ترین مفهوم برای درک شبکه های عصبی عمیق است. پس از انتشار مجدد ، همه چیز دیگر یک تکه کیک است. در این پست مختصر ، جاناتان در چند پاراگراف یک جمع بندی خلاصه می کند.
< p> انتشار مجدد دشوارترین و خسته کننده ترین مفهوم برای درک شبکه های عصبی عمیق است. پس از انتشار مجدد ، همه چیز دیگر یک تکه کیک است. در این پست مختصر ، جاناتان در چند پاراگراف یک جمع بندی خلاصه می کند.
عصمات طرح منظمی از موضوع Finding Lane Lines Porject و خط دید رایانه ای خود را ارائه می دهد استفاده شده. به طور خاص ، او توضیحات خوبی در مورد تغییر Hough ، که یک مفهوم حیله گر است ، ارائه می دهد!
معرفی Motoko Playground ، یک محیط توسعه آنلاین برای رایانه اینترنتی
معرفی Motoko Playground ، یک محیط توسعه آنلاین برای رایانه اینترنتی
زمین بازی Motoko به کاربران امکان می دهد قراردادهای هوشمند Canister را مستقیماً در یک مرورگر وب ایجاد و مستقر کنند.
توسط یان چن ، مهندس ارشد نرم افزار | DFINITY

برای ساده سازی تجربه توسعه دهندگان با استفاده از رایانه اینترنتی ، تیم زبان بنیاد DFINITY انتشار منبع باز Motoko Playground ، یک محیط توسعه یکپارچه (IDE) را که بر روی بلاک چین رایانه اینترنتی اجرا می شود ، اعلام می کند.
استفاده از Motoko ، یک زبان برنامه نویسی Motoko Playground که برای پشتیبانی یکپارچه از مدل برنامه نویسی رایانه اینترنتی طراحی شده است ، به کاربران اجازه می دهد بدون نیاز به بارگیری SDK DFINITY Canister یا راه اندازی کیف پول ، قراردادهای هوشمند Canister را مستقیماً در مرورگر وب ایجاد و مستقر کنند. از آنجا که توسعه دهندگان نیازی به ایجاد محیط توسعه خود ندارند ، این تجربه کامل در مرورگر به همه این امکان را می دهد که هنگام آزمایش برنامه نویسی در رایانه اینترنتی از هر کجا ، Motoko را کاوش و یاد بگیرند.
شروع به کار با Motoko زمین بازی
پس از ورود به dapp ، می توانید انتخاب کنید که می خواهید با چه پروژه ای کار کنید و در رایانه اینترنتی مستقر شوید. در زیر نمونه کار استفاده از زمین بازی Motoko آمده است.
مرحله شماره 1: یک پروژه نمونه را انتخاب کنید.

برای کمک به شروع سریع توسعه دهندگان جدید ، چندین پروژه Motoko از پیش نمایش نمونه های DFINITY از جمله پیشخوان ، دفترچه تلفن ، پیچ و خم تصادفی و ناشر از قبل انتخاب شده اند. /خدمات مشترکین همچنین می توانید هر کد Motoko را از Github وارد کنید.

بیایید می گویند که مثال Counter از لیست بالا انتخاب شده است. در پیوند "Main.mo" در ناوبری ، می توانید کد را مشاهده کنید.
مرحله دوم: پس از انتخاب پروژه ، روی دکمه "استقرار" در گوشه سمت راست بالا کلیک کنید تا برنامه ایجاد و استقرار شود. قوطی در رایانه اینترنتی.

پس از کلیک روی "استقرار ، ”نام قوطی را که می خواهید مستقر کنید ، مشخص کنید. در این مورد ، نام قوطی ای که مایل به استقرار آن هستید "اصلی" است. استقرار چندین ثانیه طول می کشد ، زیرا باید یک شناسه Canister رایگان از رایانه اینترنتی دریافت کرده و ماژول کامپایل شده WebAssembly (Wasm) را نصب کنید.
مرحله 3: پس از استقرار Canister ، رابط کاربری Candid در سمت راست می توان برای آزمایش کد استفاده کرد.
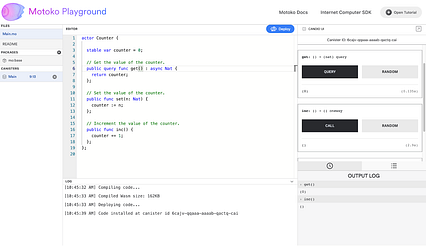
با استفاده از رابط کاربری Candid ، می توانید از طریق مرورگر با Canister ارتباط برقرار کنید - می توانید مقدار اولیه را پرس و جو کنید ، شمارنده را افزایش دهید و غیره. (در صورت تمایل ، می توانید از ابزارهای رابط خط فرمان ، مانند dfx یا ic-repl ، برای تعامل با قوطی استفاده کنید.)
مرحله 4: اگر می خواهید تغییراتی در کد را می توانید در ویرایشگر انجام دهید. به عنوان مثال ، در زیر ما روش را به get2 () تغییر داده ایم.

مرحله 5: برای استقرار مجدد ، دوباره دکمه "استقرار" را فشار دهید. از آنجا که سیستم قبلاً می داند که شما یک قوطی به نام "Main" دارید ، باید مشخص کنید که آیا می خواهید قوطی موجود را ارتقا دهید یا یک قوطی جدید را به طور کامل نصب کنید. با مثال زیر ، قوطی موجود را ارتقا می دهیم.

مرحله 6: از آنجا که شمارنده در حافظه پایدار است ، پس از ارتقا ، هنگامی که روش جدید get2 را فرا می گیرید ، شمارنده را برمی گردانداز آخرین بار (به جای 0) به عنوان مقدار اولیه.
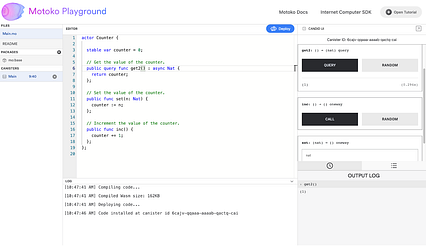 < مرحله 7: زمین بازی Motoko از آرگومان های نصب پشتیبانی می کند. در مثال زیر ، می توانید یک کلاس بازیگر برای شمارنده اضافه کنید.
< مرحله 7: زمین بازی Motoko از آرگومان های نصب پشتیبانی می کند. در مثال زیر ، می توانید یک کلاس بازیگر برای شمارنده اضافه کنید.  < /img>
< /img> مرحله 8: هنگامی که می خواهید قوطی خود را مستقر کنید ، سیستم می داند که یک آرگومان نصب وجود دارد و مقدار شروع شمارنده را درخواست می کند. در مثال ، مقدار شروع در حال حاضر 42 است و می توانید قوطی را دوباره نصب کنید.

مرحله 9: اکنون ، هنگامی که مقدار اولیه را درخواست می کنید ، شمارنده مقدار 42 را باز می گرداند ، همانطور که در هنگام استقرار مشخص کرده بودید.
برای پروژه های بزرگ ، توسعه دهندگان معمولاً باید از کتابخانه های Motoko شخص ثالث استفاده کنند. زمین بازی Motoko از مجموعه بسته کشتی ، که مجموعه ای از کتابخانه های Motoko است که از جامعه نگهداری می شود ، پشتیبانی می کند. شما می توانید این کتابخانه ها ، مانند تجزیه ، SHA256 و کتابخانه های مختلف ساختار داده را با کلیک روی دکمه "+" در بخش بسته ها در ستون سمت چپ وارد کنید.
Motoko Playground از ویژگی های مشابه شما پشتیبانی می کند. محیط توسعه محلی ، مانند فراخوان های بین کانتری ، ارتقاء کانیستر ، نصب کلاس بازیگر با آرگومان های راه اندازی اولیه و کتابخانه های شخص ثالث. به عنوان یک تمرین جالب ، توسعه دهندگان تشویق می شوند که مخزن CanCan را وارد کنند ، کتابخانه "sequence" را از قسمت بسته اضافه کنند و قوطی پشتی را در زمین بازی Motoko در داخل یک مرورگر وب بسازند.
علاوه بر این نسخه مستقل Motoko Playground ، یک نسخه تعبیه شده نیز وجود دارد که در دفترچه راهنمای زبان Motoko استفاده می شود. این یک نسخه سبک از Motoko Playground است که در آن کاربران می توانند به صورت تعاملی کد موجود در اسناد را تغییر داده و بدون نیاز به نصب کد در رایانه اینترنتی ، کد را فوراً در مرورگر اجرا (تفسیر) کنند.
چگونه زمین بازی Motoko
همه کد منبع بازی Motoko اکنون عمومی است. توسعه دهنده ای که کد را مرور می کند ، یک برنامه وب کامل با یک جاوا اسکریپت جلویی و یک قوطی پشتی پیدا می کند که چرخه های رایگان را که در Motoko و Rust نوشته شده است مدیریت می کند.
برخلاف اکثر موارد آنلاین IDE ها ، کامپایلر Motoko به لطف کامپایلر js-of-ocaml در قسمت جلویی میزبانی می شود. این به طور خودکار نگرانی های امنیتی و مقیاس پذیری را برطرف می کند ، زیرا کامپایلر به جای سرور از راه دور در مرورگر کاربر اجرا می شود. به طور خاص ، قسمت جلویی از اجزای زیر تشکیل شده است: برجسته سازی و اعتبار سنجی نحو Motoko.
چرخه های رایگان و قسمت پشتی
برای پشتیبانی از پذیرش برنامه نویس ، DFINITY تهیه چرخه های رایگان برای قوطی های مستقر در زمین بازی Motoko ، به طوری که کاربران جدید مجبور نباشند یک کیف پول چرخه برای کاوش Motoko و رایانه اینترنتی تنظیم کنند.
قوطی پشتی به Motoko نوشته شده است و مدیریت می کند چرخه های رایگان که توسط قوطی های مستقر استفاده می شود. برای اطمینان از استفاده عادلانه از این چرخه های رایگان ، محدودیت هایی برای قوطی های مستقر وجود دارد: هر قوطیتعادل چرخه اولیه 0.5T است و فقط می تواند 10 دقیقه اجرا شود. انتقال چرخه از طریق قوطی ها نیز مجاز نیست.
بطور خاص ، هنگامی که قسمت جلویی یک قوطی جدید درخواست می کند ، قسمت عقب یک قوطی رایگان در حوضچه قوطی خود می یابد ، چرخه های آن را بالا می آورد و مدت انقضا را تنظیم می کند. از این قوطی پس از اتمام زمان انقضا ، قسمت پشتی می تواند این قوطی را به سایر کاربرانی که درخواست استقرار دارند ، بدهد. برای جلوگیری از اشغال بیش از حد یک قوطی تنها ، هنگام کار درخواست کاربر برای قوطی جدید ، نیاز به اثبات کار است.
برای اطمینان از انصاف منابع ، می خواهیم از انتقال تعداد زیادی چرخه به کاربران جلوگیری کنیم. قوطی های مخصوص خودشان به عنوان مثال ، می توانید به راحتی با فراخوانی روش depos_cycles در قوطی مدیریتی ، همه چرخه های موجود در قوطی بازی مستقر در زمین بازی را به قوطی مورد نظر منتقل کنید. برای جلوگیری از این حمله ، ما تمام ماژول های ارائه شده Wasm را بازرسی کرده و دستورالعمل های انتقال چرخه را در سطح Wasm حذف می کنیم. از آنجا که Motoko در حال حاضر کتابخانه تجزیه و تحلیل Wasm ندارد ، برای دستیابی به این هدف از قوطی Rust استفاده می شود. هر بار که Motoko درخواست نصب دریافت می کند ، ماژول Wasm را برای بازرسی به Rust Rust ارسال می کند. این در واقع الگوی جالبی است که از پشتیبانی FFI در Motoko تقلید می کند.
در آینده ، وقتی کاربران کیف پول خود را برای استقرار تهیه کنند ، که موارد استفاده پیشرفته تری را امکان پذیر می کند ، این محدودیت ها کاهش می یابد.
< p> ما قصد داریم بسیاری از ویژگی های دیگر را اضافه کنیم تا Motoko Playground را به عنوان یک IDE وب کامل برای رایانه اینترنتی تبدیل کنیم. از مشارکت های جامعه استقبال زیادی می شود!در همین حال ، امیدواریم از جستجوی راحت Motoko ، زبان مادری رایانه اینترنتی ، مستقیماً در مرورگر وب ، بدون بارگیری SDK لذت ببرید. توسعه دهندگان علاقه مند همچنین تشویق می شوند تا کد منبع باز Motoko Playground را مرور کنند. ____ شروع به ساختن در sdk.dfinity.org کنید و به انجمن توسعه دهندگان ما در forum.dfinity.org بپیوندید.